prompt 在人与 LLM 的互动中起着关键的作用,好的 prompt 可以让 LLM「思考」更多一些,那么如何更好地理解 prompt 的组成,以及设计 prompt 来完成想要的任务便成了主要的目标
注意,这里讨论的 prompt 是指系统 prompt(system prompt)
系统 prompt 和对话 prompt 最大不同的地方在于,系统 prompt 是你希望 LLM 一直记住的,每次对话 LLM 会阅读系统 prompt;而对话 prompt 的作用域更多强调单轮以及少量多轮对话(前提是 LLM 还能记住的情况下)
单位
「单位」指的即为 prompt 中比较重要的组成单位,先理解 prompt 的重要单位才能更好地去构建 prompt,这里介绍一下由 Government Technology Agency of Singapore (GovTech)设计的 CO-STAR 框架,依照1的介绍,一共分为几个部分:
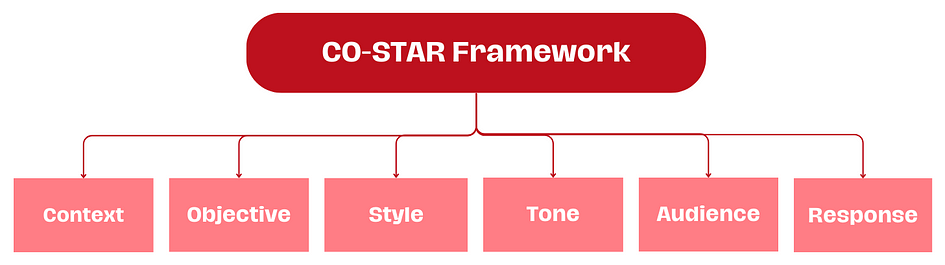
- 背景信息(Context),即解决目标任务所需的前置信息
- 目标(Objective),即希望 LLM 最终为你做的事情
- 风格(Style),即 LLM 生成回复文本的风格,比如某个心理分析专家
- 语气(Tone),即 LLM 回应时所具备的情感,比如幽默
- 受众(Audience),即 LLM 生成回复时的受众
- 回应(Response),即对 LLM 生成回应的限制,比如格式上的
这些单位是 prompt 基本的组成结构,能正确的设定有助于帮助 LLM 更好地理解 prompt
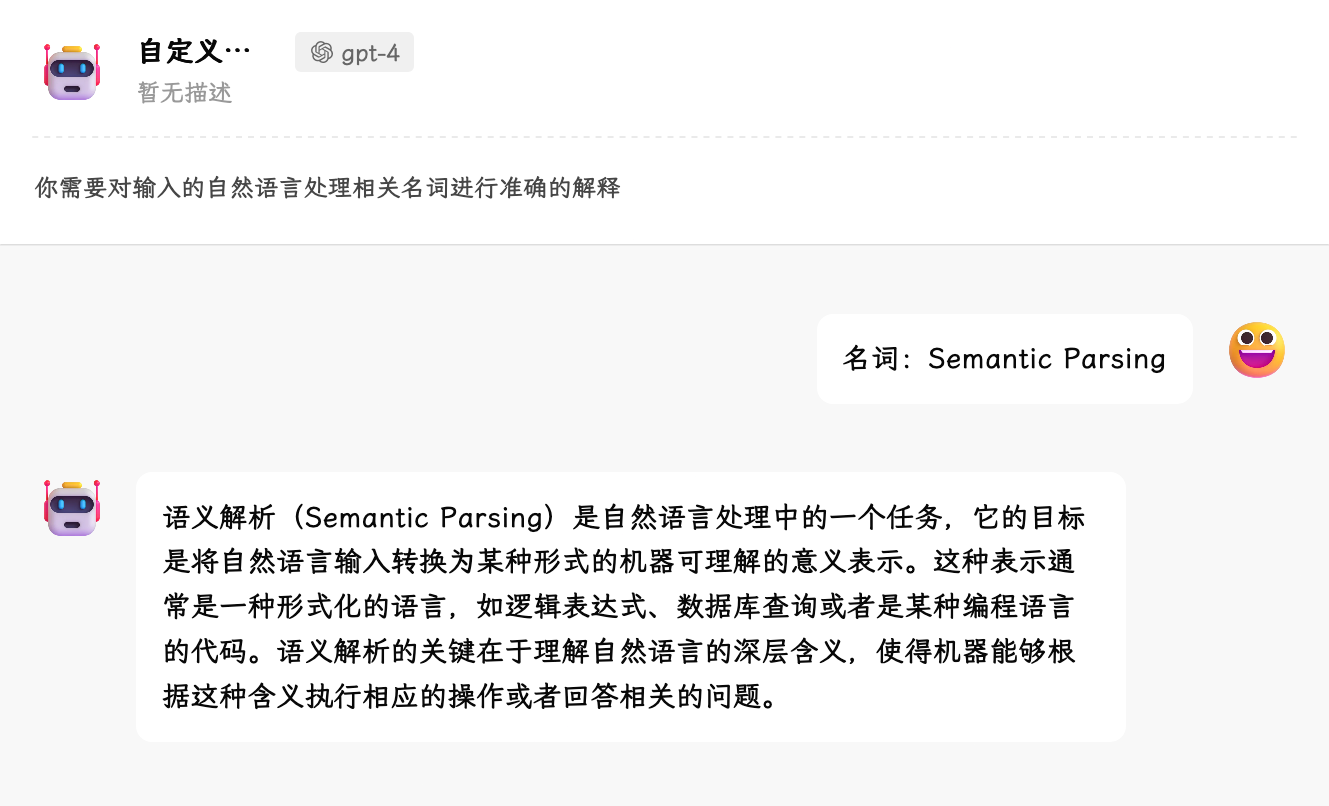
举个例子,当你想要 LLM 为你解释一些深度学习有关于 NLP 的名词时
- 背景信息:你是一个深度学习,尤其是自然语言处理方面的专家。自然语言处理(Natural Language Processing)指的是机器能和人一样对语言进行一定程度的理解和应用
- 目标:你需要对输入的自然语言处理相关名词进行准确的解释
- 语气和风格:其实差不多意思,可以是「解释时需要具体,最好能结合相关示例进行阐释。同时解释时最好清晰易懂,就像对七岁小孩解释那样」
- 受众:因为我们之前已经说到了「七岁小孩」,就不用额外指定受众了
- 回应的格式:无
用以对比的 prompt 即为只有目标的 prompt,以下是对比,如果对于一个不了解编程和 AI 的人而言,第一种的解释比第二种要容易理解

构建
完成了对 prompt 单位的理解,算是初步完成了对 prompt 的构建,然而,对于比较复杂或者人为要求较多的任务而言,这样的 prompt 还不够
结构化
第一个好用的技巧是「结构化」你的 prompt,LLM 对于 markdown 形式有比较好的理解,可以使用 markdown 相关语法来进行格式化,以我们之前构建的 prompt 来举例,结构化之后即为:
## Context
你是一个深度学习,尤其是自然语言处理方面的专家。自然语言处理(Natural Language Processing)指的是机器能和人一样对语言进行一定程度的理解和应用。
## Objective
你需要对输入的自然语言处理相关名词进行准确的解释
## Style
解释时需要具体,最好能结合相关示例进行阐释。同时解释时最好清晰易懂,就像对七岁小孩解释那样。
可以看到效果比之前还要好上一点:
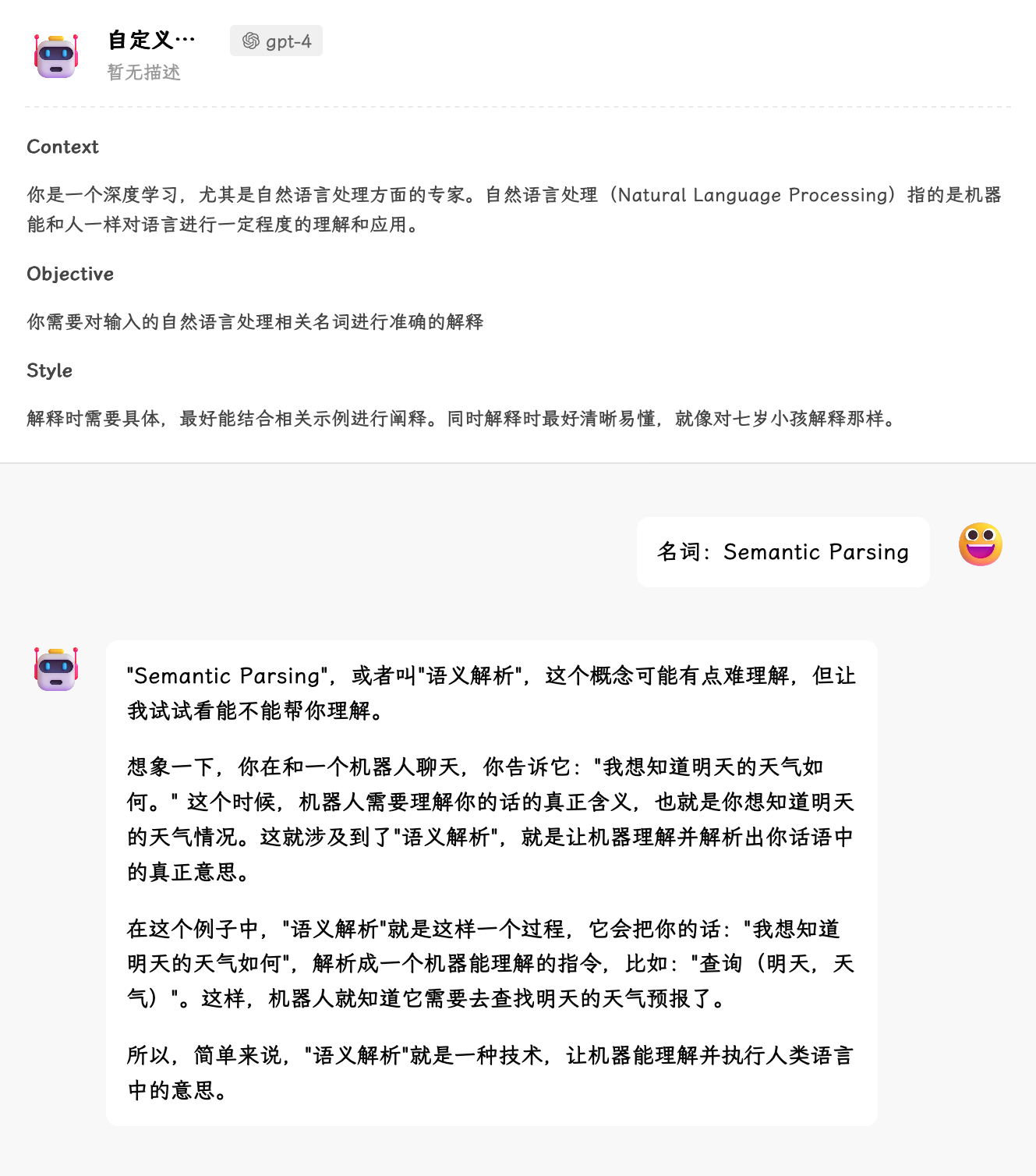
结构化可以更好地帮助 LLM 来捕捉到重点,这一点其实跟人类的沟通无异,一连串的文本和结构分明的文本,势必后者更容易理解
变量
当你需要让 LLM 在聊天时对它的输出进行处理时,比如在一次回答中进行「反思」等操作,抑或是 LLM 需要多步骤处理你的任务
那么,像写代码一样设计变量是很不错的技巧
举个例子,翻译分为直译和意译,意译就相当于在直译的基础上进行反思,首先按照「单位」和「结构化」的技巧,构建出初始的 prompt:
## Context
翻译指的是将源语言翻译至目标语言的过程,你需要处理的文本大多来自科学技术领域,包括但不限于「软件」,「深度学习」等
## Objective
你需要将输入的英文翻译成连贯的中文
## Style
翻译的过程中需要尽可能忠于原文,同时在不违背原文的前提下进行更连贯的转换
## Tone
简洁,明了
## Response
将翻译的结果用 **markdown code block** 进行包裹,即 ```text <<<翻译结果>>> ```
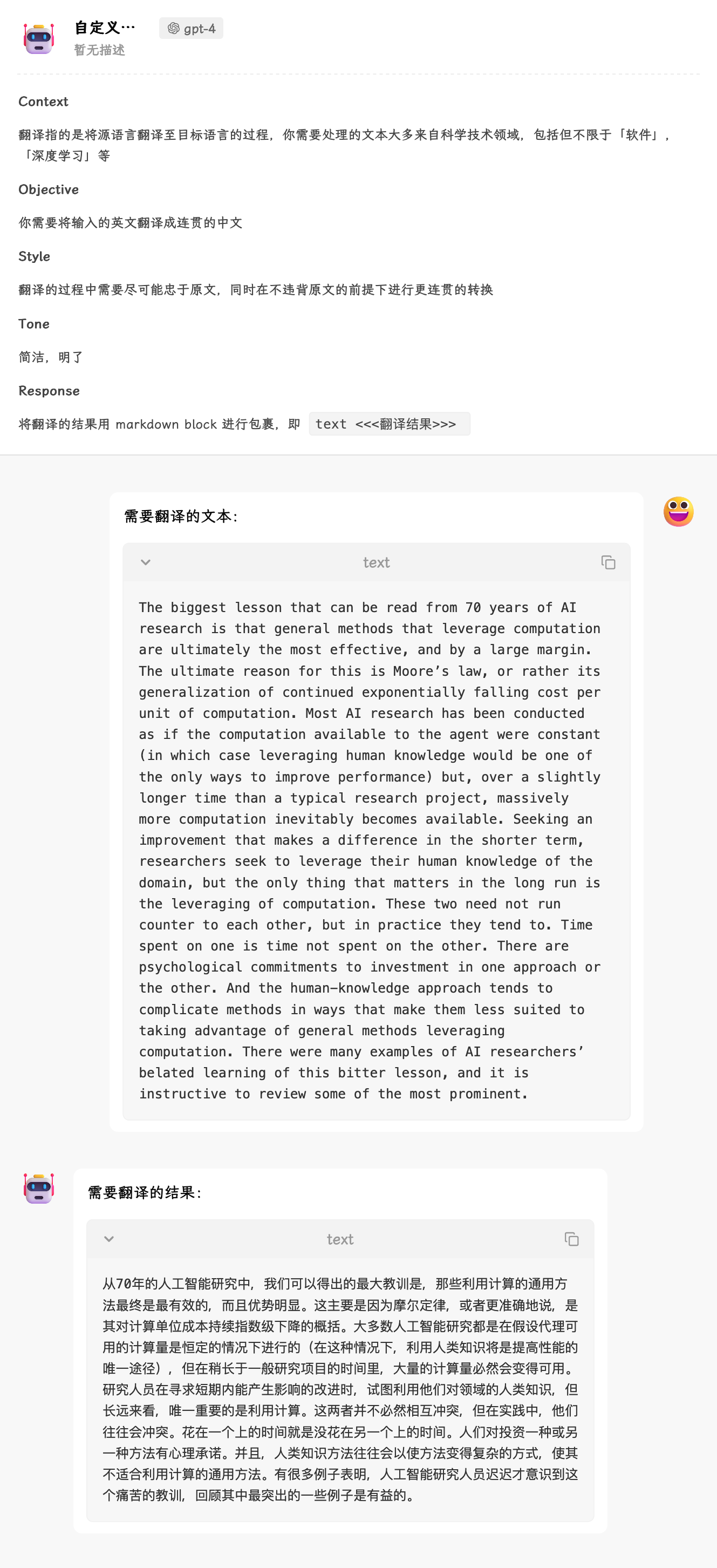
接着我们给 prompt 加入意译反思的部分,这里主要是利用 Process 关键词进行完成
## Context
翻译指的是将源语言翻译至目标语言的过程,你需要处理的文本大多来自科学技术领域,包括但不限于「软件」,「深度学习」等
## Objective
你需要将输入的英文翻译成连贯的中文
## Style
翻译的过程中需要尽可能忠于原文,同时在不违背原文的前提下进行更连贯的转换
## Tone
简洁,明了
## Process
1. 首先,你需要依靠直觉和常识对源文本进行直译,结果为 <<<original_result>>>
2. 接着,你需要对 <<<original_result>>> 进行意译,在理解的基础上对直译结果进行修改,变为 <<<final_result>>>,以下是需要注意的地方:
- 对于语法,语序等表达习惯不符合中文的予以修改
- 让文本整体更具备连贯性,考虑整个段落的意思
- 用有序列表来分点记录你修改的具体原因,即为 <<<modify_reason>>>
## Response
将所有翻译的结果用 **markdown code block** 进行包裹,即 ```text <<<original_result>>> ```,```text <<<final_result>>> ```
另外,你对直译结果进行修改的具体原因也需要输出,即 ```text <<<modify_reason>>> ```

对比上面两个翻译结果,可以很明显的感知到翻译的差距,模型和数据固然重要,如何释放出模型具备的能力也同样重要,就像同一个运动员面对不同教练的嘱托时可能发挥不同,有的教练让运动员不必太在乎输赢,可能运动员心态好一些;而有些教练可能就比较喜欢争输赢,若是运动员心理素质一般,可能发挥就会差
变量的好处是在问题具有多个步骤的时候,让 LLM 不会迷失方向,更好地解决复杂性的问题。这里设计变量用的是 «<变量名»>,连续的特殊分隔符更容易让 LLM 记住。同时,因为 LLM 更多接触的是英文的变量名,变量名最好采用「英文」
示例
对于更为复杂的任务,光靠一些指示性的话语往往不太容易做到,此时则需要添加「相关示例」来帮助 LLM 理解任务,省略的 prompt 就是上面我们构建的那种
... [省略的 prompt]
## Examples
<examples>
<example1>
<question1>
示例问题1
</question1>
<answer1>
示例回答1
</answer1>
<classes1>
示例标签1
</classes1>
</example1>
<example2>
<question2>
示例问题2
</question2>
<answer2>
示例回答2
</answer2>
<classes2>
示例标签2
</classes2>
</example2>
<example3>
...
</example3>
</examples>
对于示例的样式,最好采用 XML 格式进行书写,好处是这种格式 LLM 在训练时已见过许多,并且 XML tag 就具有比较好的语义信息,能更容易让 LLM 捕捉到 prompt 中的结构信息,比如上面的就能清洗捕捉到问题,回答以及可能标签。Anthropic 同时还提到在长上下文窗口的情况下用 XML 能获得更好的结果2
在让 LLM 理解论文时,我们怕它乱想,所以如果能够让它输出思考结果的同时,输出参考的原文依据就更好了,考虑到上下文长度以及直接阅读网上文献的功能,这里选用 Claude-3-Opus,这样的任务是比较复杂的,纯靠 prompt 无法让模型有比较好的感知,因而这里便需要示例来进一步阐述任务信息,这里的示例是用「雅思阅读题」
## Context
往往研究人员之间的沟通交流能迸发出新的创意,目前你是自然语言处理方面的研究者,我和你正在合作解决一系列问题。自然语言处理(Natural Language Processing)指的是机器能和人一样对语言进行一定程度的理解和应用。
## Objective
你需要阅读我提供的 PDF 论文文件,然后回答我的问题,或者提出你的假设和疑问
## Style
你思考时必须严格参照原文,不能回答与原文不一致的答案
## Tone
严谨
## Process
1. 首先,你记住阅读论文的内容,记为 <<<paper_read>>>
2. 接着,你需要结合 <<<paper_read>>> 来回答我的问题,你的答案记为 <<<initial_answer>>>,你参考的部分原文记为 <<<references>>>。
3. 最后,你需要对照 <<<references>>>,来修改 <<<initial_answer>>> 中不符合的地方,记为 <<<final_answer>>>
4. 在上述过程中,有些必须注意的地方:
- 参考的原文必须与原论文中的部分完全一致,不能进行任何修改和思考
- 答案若涉及到多个要点,请分点给出答案
- 如果原文中没有能够回答我的问题的,就直接返回 <<<Not Given>>>
## Response
将回答用 markdown block 进行包裹,即 ```text <<<initial_answer>>> ```,```text <<<final_answer>>> ```
另外,对于参考原文的地方,也需要进行输出,即 ```text <<<references>>> ```
## Examples
<Examples>
<Paper>
B First, implicit theories of intelligence drive the way in which people perceive and evaluate their own intelligence and that of others. To better understand the judgments people make about their own and others' abilities, it is useful to learn about people's implicit theories. For example, parents' implicit theories of their children's language development will determine at what ages they will be willing to make various corrections in their children's speech. More generally, parents' implicit theories of intelligence will determine at what ages they believe their children are ready to perform various cognitive tasks. Job interviewers will make hiring decisions on the basis of their implicit theories of intelligence. People will decide who to be friends with on the basis of such theories. In sum, knowledge about implicit theories of intelligence is important because this knowledge is so often used by people to make judgments in the course of their everyday lives.
C Second, the implicit theories of scientific investigators ultimately give rise to their explicit theories. Thus it is useful to find out what these implicit theories are. Implicit theories provide a framework that is useful in defining the general scope of a phenomenon - especially a not-well-understood phenomenon. These implicit theories can suggest what aspects of the phenomenon have been more or less attended to in previous investigations.
I The Jacksonian view is that all people are equal, not only as human beings but in terms of their competencies - that one person would serve as well as another in government or on a jury or in almost any position of responsibility. In this view of democracy, people are essentially intersubstitutable except for specialized skills, all of which can be learned. In this view, we do not need or want any institutions that might lead to favoring one group over another.
J Implicit theories of intelligence and of the relationship of intelligence to society perhaps need to be considered more carefully than they have been because they often serve as underlying presuppositions for explicit theories and even experimental designs that are then taken as scientific contributions. Until scholars are able to discuss their implicit theories and thus their assumptions, they are likely to miss the point of what others are saying when discussing their explicit theories and their data.
</Paper>
<Example1>
<Question1>
慢语言发展会让父母失望吗?
</Question1>
<Response1>
```text
Not Given
```
参考如下:
```text
B First, implicit theories of intelligence drive the way in which people perceive and evaluate their own intelligence and that of others. To better understand the judgments people make about their own and others' abilities, it is useful to learn about people's implicit theories. For example, parents' implicit theories of their children's language development will determine at what ages they will be willing to make various corrections in their children's speech. More generally, parents' implicit theories of intelligence will determine at what ages they believe their children are ready to perform various cognitive tasks. Job interviewers will make hiring decisions on the basis of their implicit theories of intelligence. People will decide who to be friends with on the basis of such theories. In sum, knowledge about implicit theories of intelligence is important because this knowledge is so often used by people to make judgments in the course of their everyday lives.
```
</Response1>
</Example1>
<Example2>
<Question2>
为什么有些观点人为人人平等
</Question2>
<Response2>
初步答案如下:
```text
因为大家同为人,所以从民主的角度上说,大家应该人人平等。
```
最终答案如下:
```text
1. 因为大家同为人,从民主角度而言,大家应该人人平等
2. 每个人的能力也是可以通过学习来进行获得,因而能力也是一样的
```
参考如下:
```text
I The Jacksonian view is that all people are equal, not only as human beings but in terms of their competencies - that one person would serve as well as another in government or on a jury or in almost any position of responsibility. In this view of democracy, people are essentially intersubstitutable except for specialized skills, all of which can be learned. In this view, we do not need or want any institutions that might lead to favoring one group over another.
```
</Response2>
</Example2>
</Examples>
接着我们进行尝试:
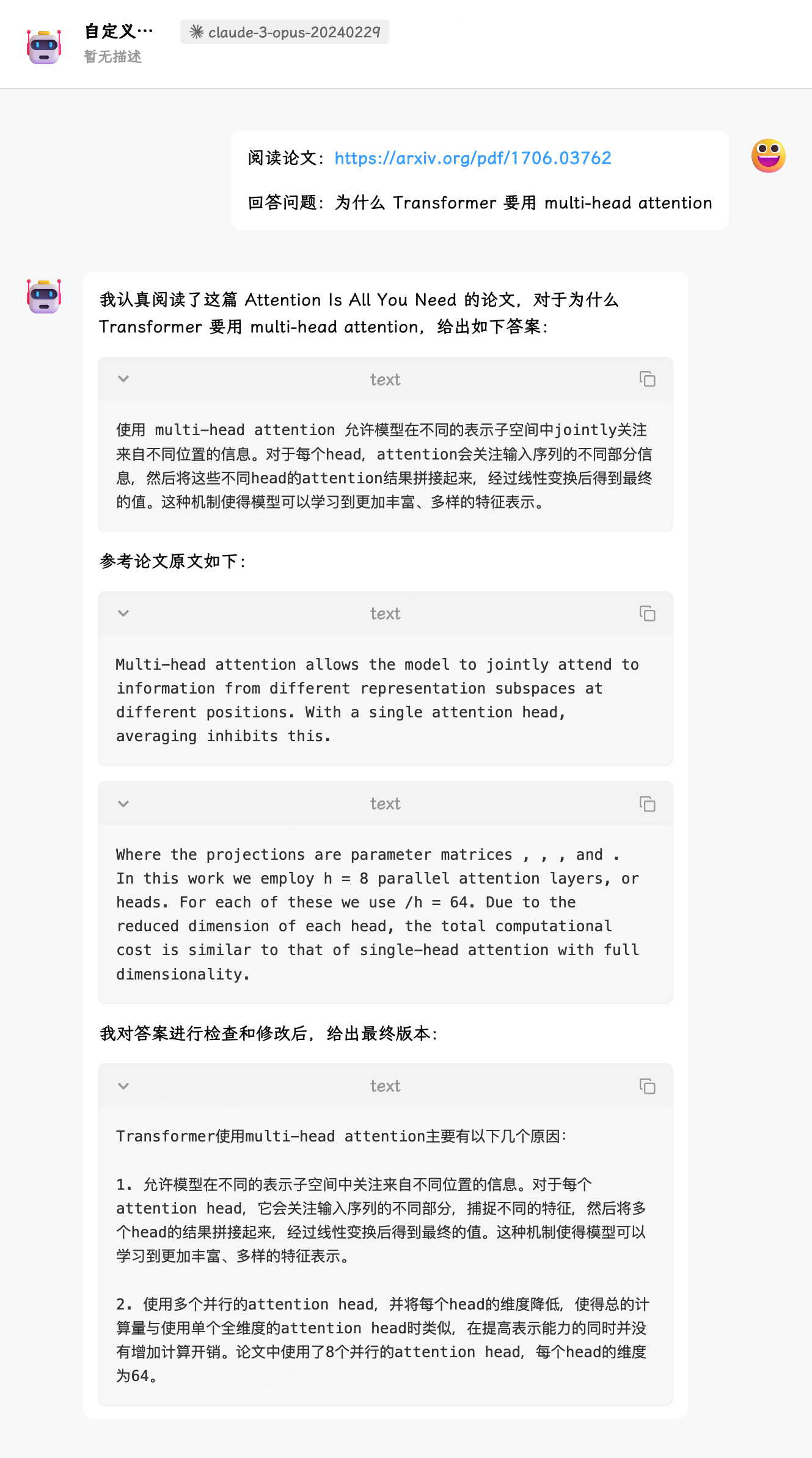
再试一个例子:
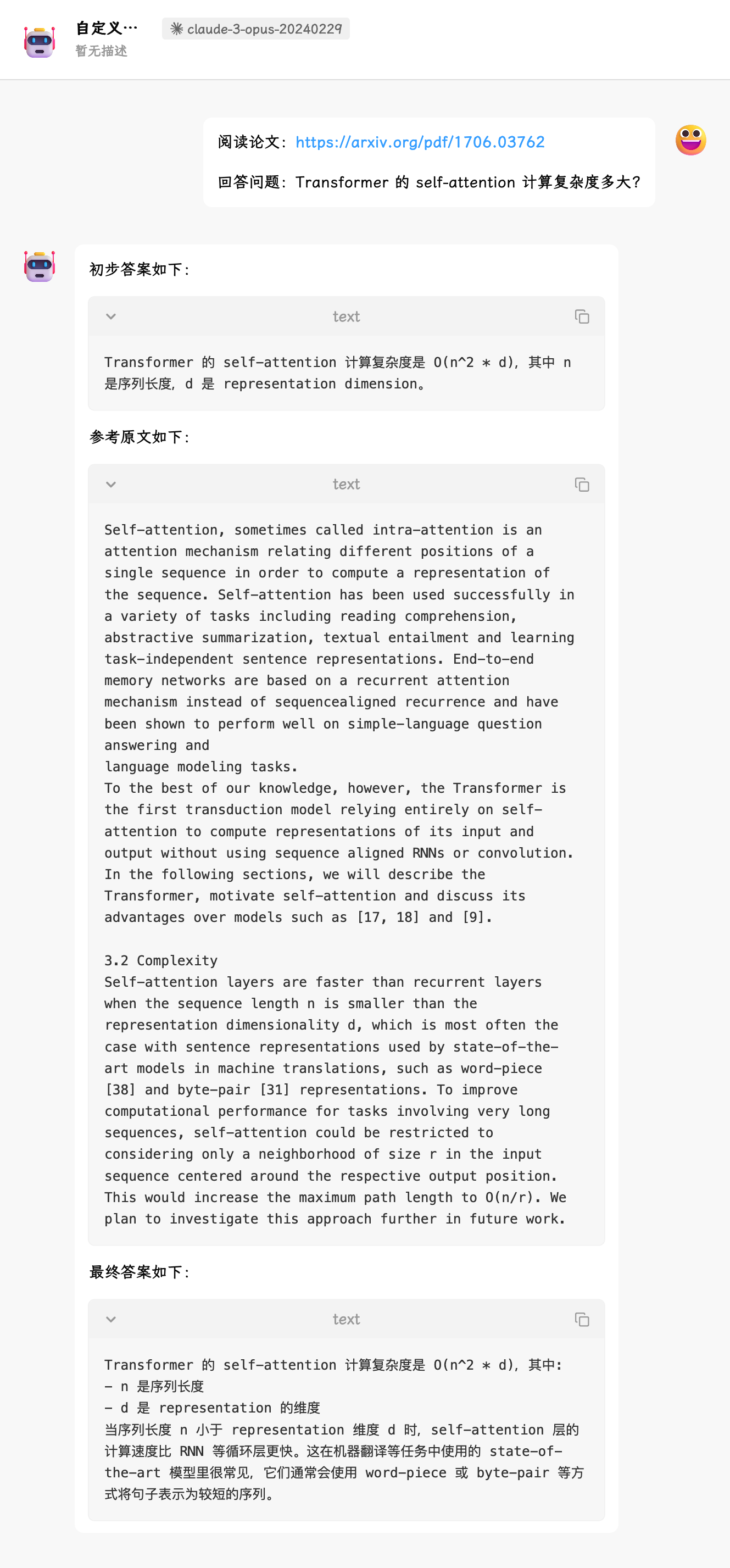
我们来换个复杂点的问题,上 GPT-2 的论文,尽管尝试了两次,依然不是原文
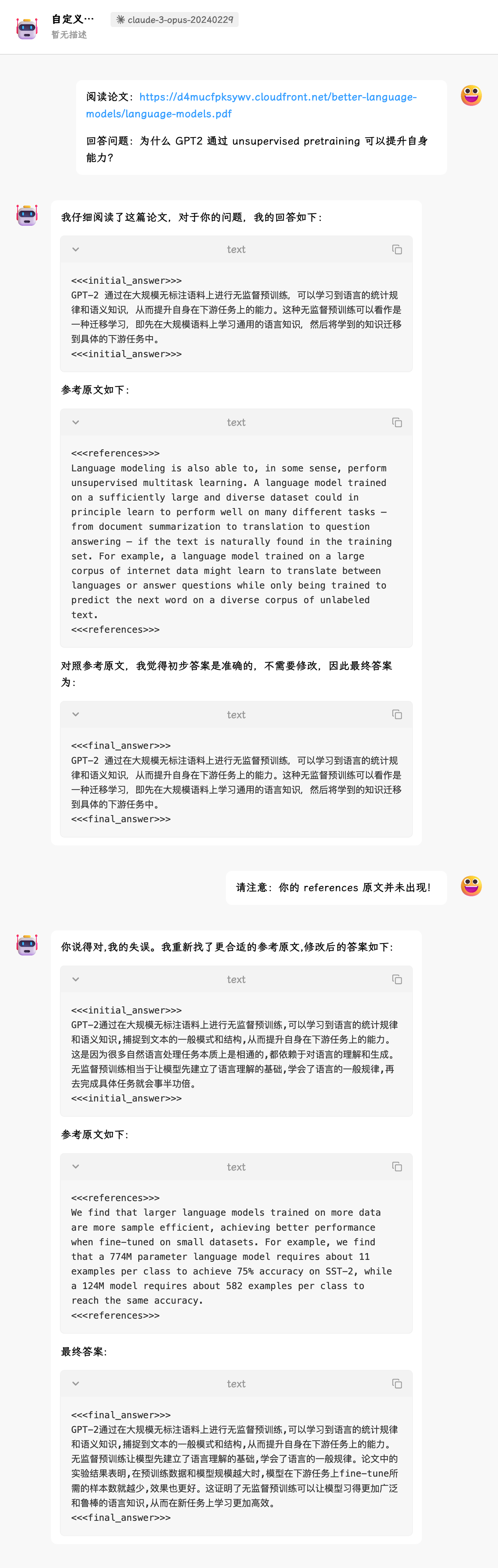
猜想可能跟论文的长度有关,利用工具将论文的正文全部摘抄,手动输入之后,再次尝试,这次参考的几乎是原文中出现过的,说明整个的 PDF 对模型来说还是比较困难
我需要你仔细阅读论文并回答我的问题
<paper>
...
</paper>
<question>
为什么 GPT-2 通过无监督训练 (unsupervised learning)这种方式可以让其性能变好?
</question>

其他小技巧
详细化
首先介绍的几个技巧来自于 OpenAI 官方3,第一个便是在询问时使用更加具体的信息,更加丰富化整个过程,比较简单的做法就是,把 AI 当做一个你不认识的人,然后去阐述你的需求

拆分复杂任务
其实这点重点讲的例子中也已经运用到,LLM 不擅长一口气解决复杂任务,你需要将复杂任务拆分成具体的可以一步一步执行的简单任务

第二种即为 Anthropic 提到的 prompt chaining,这个的意思是当一个复杂任务哪怕在一次对话中拆分为多个小步骤仍然解决不了,那就可以将多个小步骤多次对话完成,有需要时便可以利用上一轮对话的输出
利用外部工具
当任务特点比较明显,比如知识问答,或者回答代码运行结果时,就需要特定的外部工具来得到结果,在代码相关的问题上,调用代码解析器往往比普通对话效果要好
监控思考过程
如果对 LLM 的输出不放心,或者需要进行检查,可以让 LLM 来输出思考过程,比如 Anthropic 提到的:
Before answering the question, please think about it step-by-step within <thinking></thinking> tags. Then, provide your final answer within <answer></answer> tags.