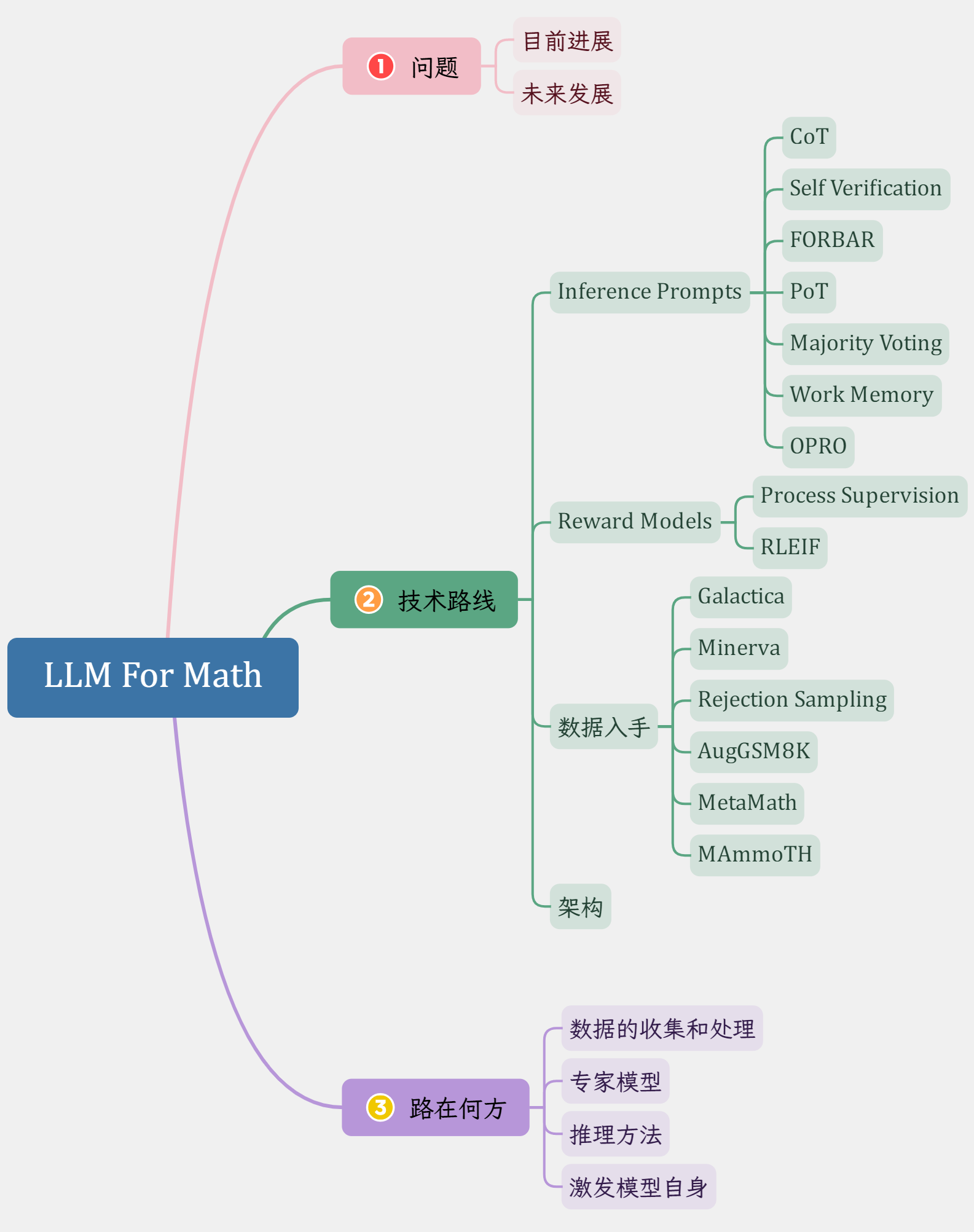
问题
LLM 通过大量的语料来建模下一个 token 的概率,这种训练方式促成 LLM 成为一个「文科生」,那么我们不禁对以下几个问题好奇:
- LLM 目前在数学问题上取得的进展
- 有哪些技术路线在未来可能会更进一步提升 LLM 解决数学问题的能力?
在以下部分不妨来讨论上面两个问题
技术路线
那么在目前的模型中,分别有哪些方案呢?这里只会介绍各种路线关于数学的 key points,不会特别关注其他细节。另外 MathGPT 和 Abel 目前没有详细的 report,不会涉及
Inference Prompts
LLM 直接输出答案经常会出错,第一条路线是通过 prompt 的不同方法来让模型不断「shift the distribution」,让模型不断调整输出分布,让结果更稳定和准确
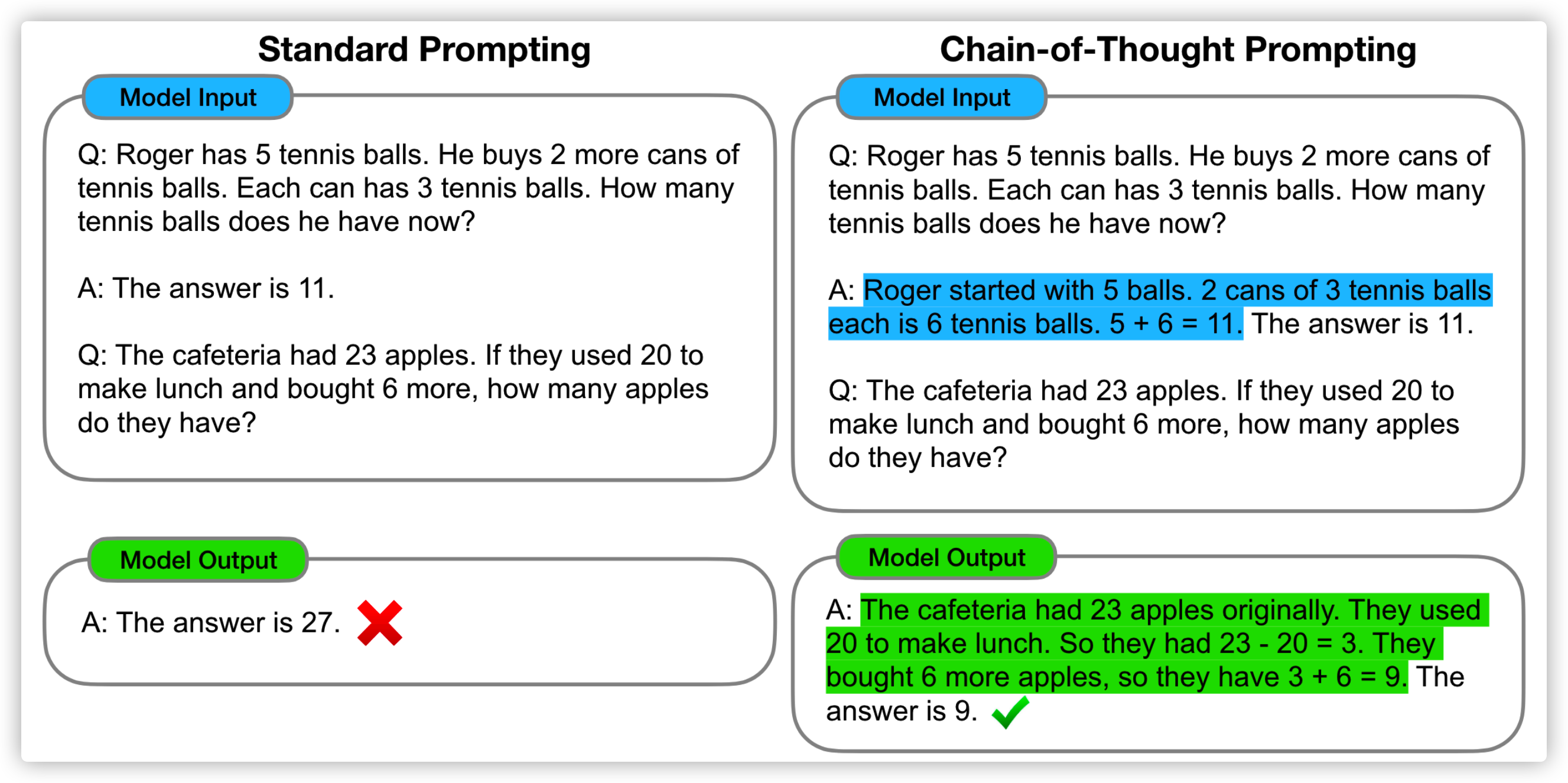
CoT
众所周知,CoT(Chain of Thought)是一种通过让模型一步步思考来提高模型推理能力的,下图右侧是 CoT
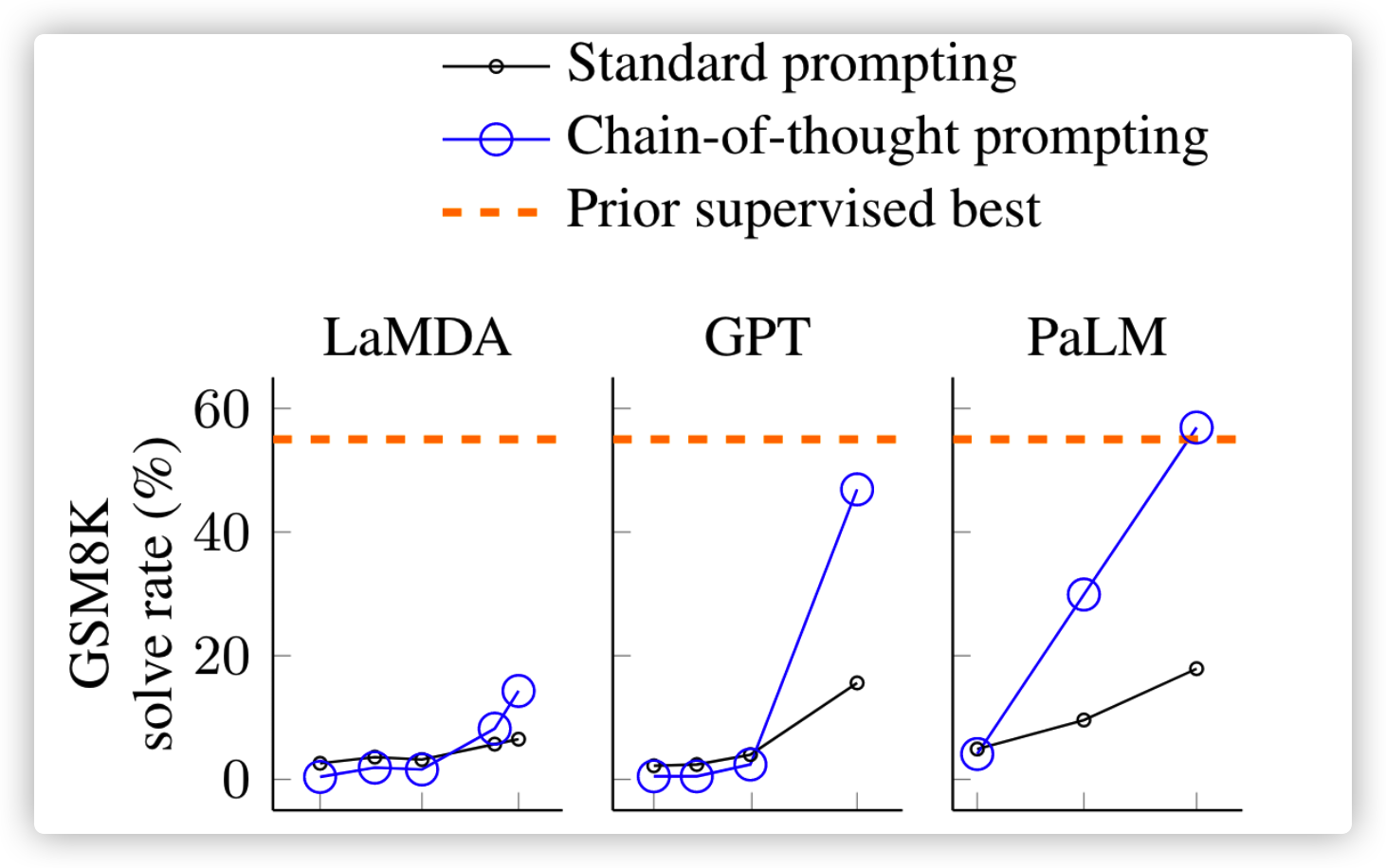
下图横轴代表参数规模,当时通过 CoT 在 PaLM 上甚至超过了监督训练的 SOTA,CoT 这种方法就感觉像是「refine 模型输出的分布」,一步步思考也就意味着输出尽可能往正确的上面靠,相比之下,直接输出就像是「一锤定音」
Self-Verification
这篇工作就是进行反向验证,这篇工作看到还是比较开心的,刚好验证了自己之前的猜想
举个例子来说,我们问模型一个问题,模型回答了两种答案:
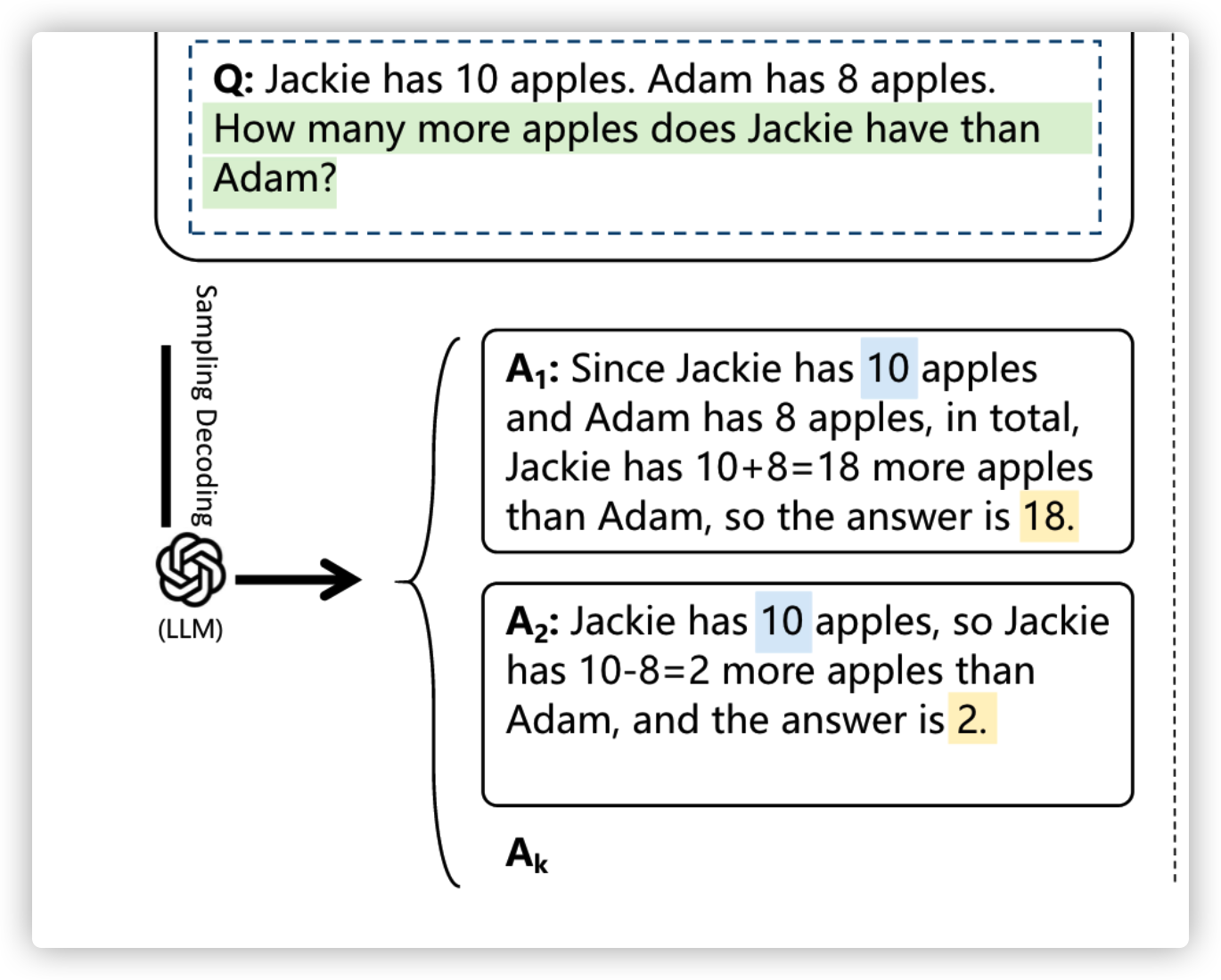
接下来我们将这个答案作为已知量,将题干中的变量当做未知,去反推,发现不一致,则说明答案有误

FORBAR
FORBAR 代指的是 Forward-Backward Reasoning,跟上面几乎一致,可以看个例子:
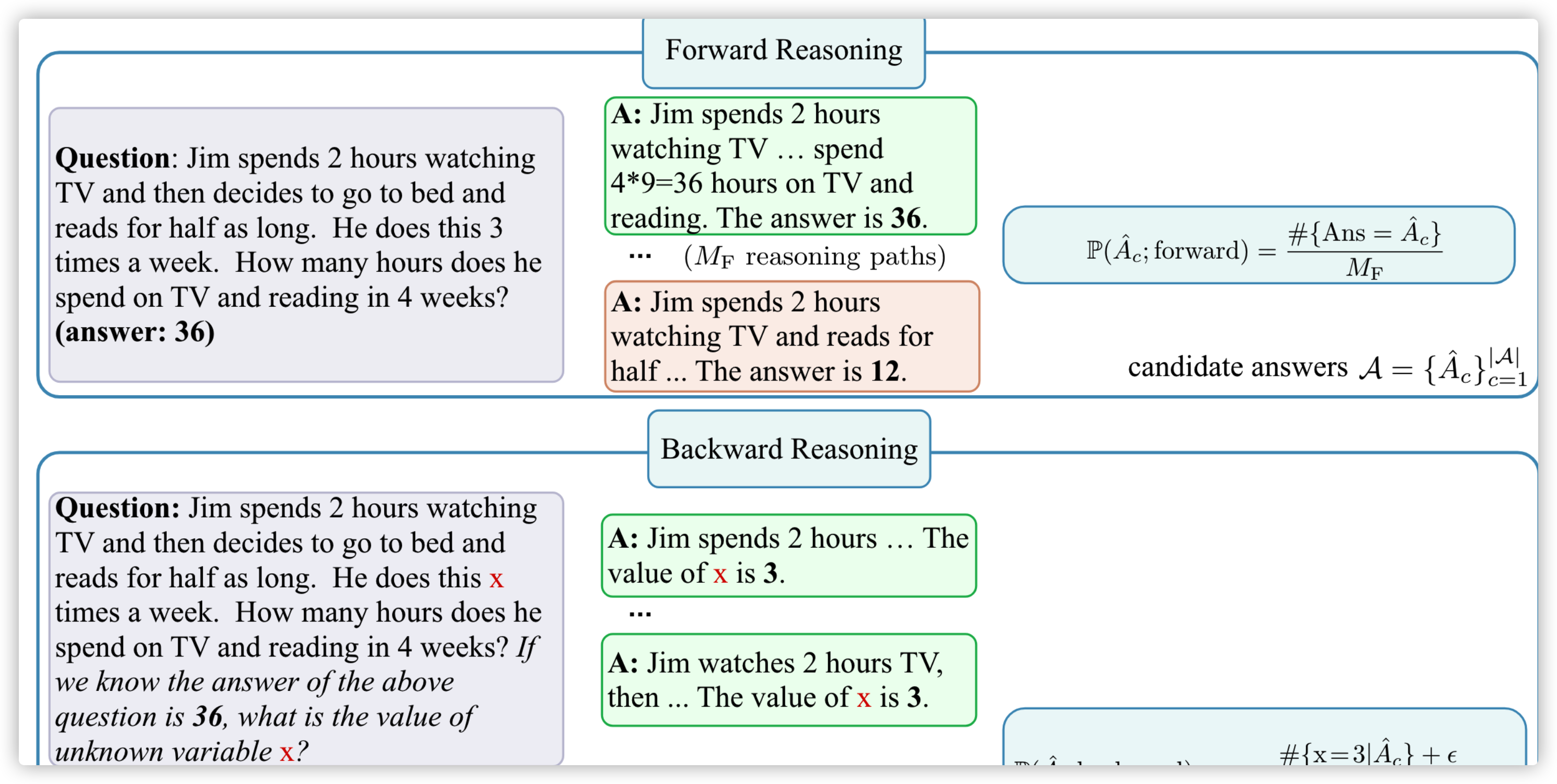
Forward 就是我们之前让模型直接算的,而 Backward 的意思就是我把题干中的一个变量给遮盖掉,变成 x,而我告诉你答案,我要反问你 x 是啥
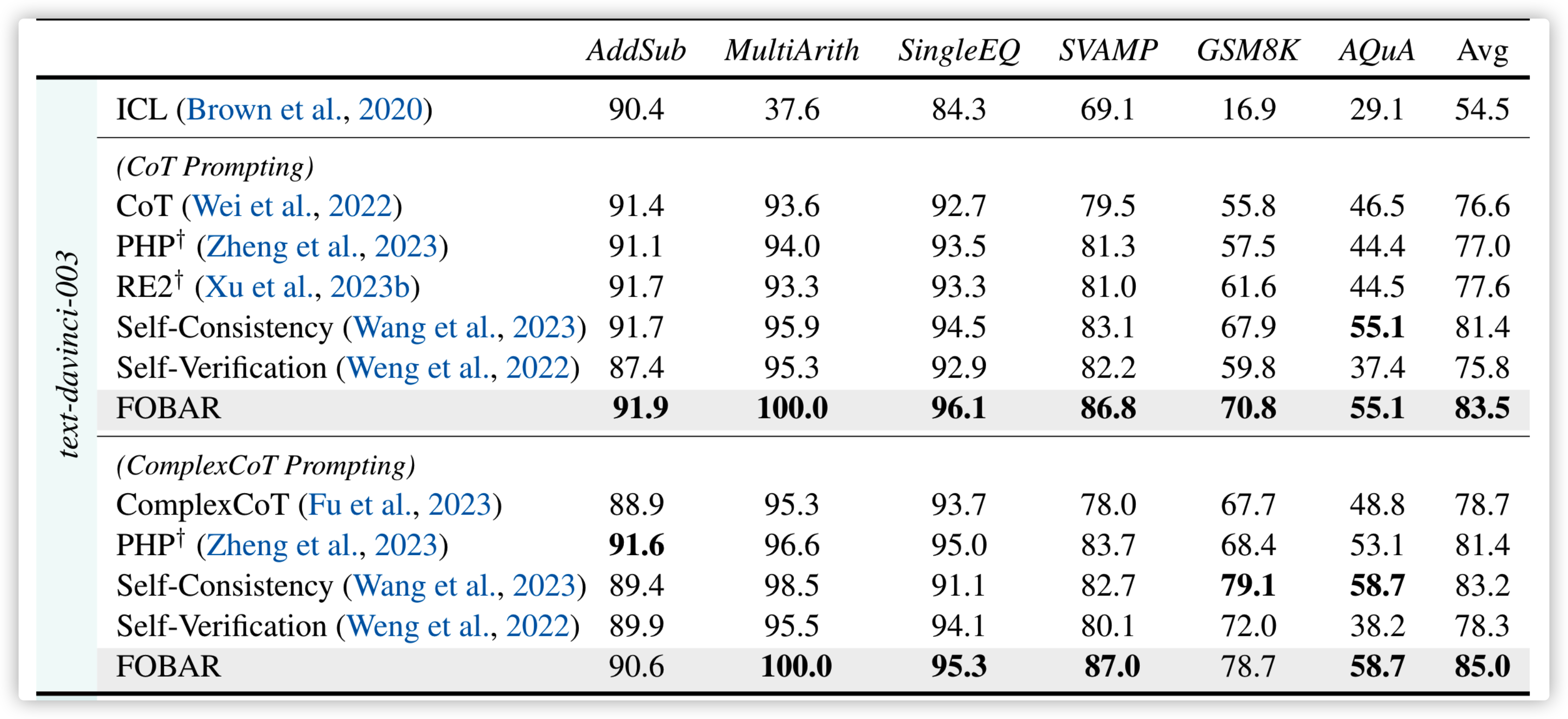
不同的是 Self-Verification 是用以验证,不能扩充成为 Examples,而 FORBAR 就可以作为 Examples
效果是相当不错的:
PoT
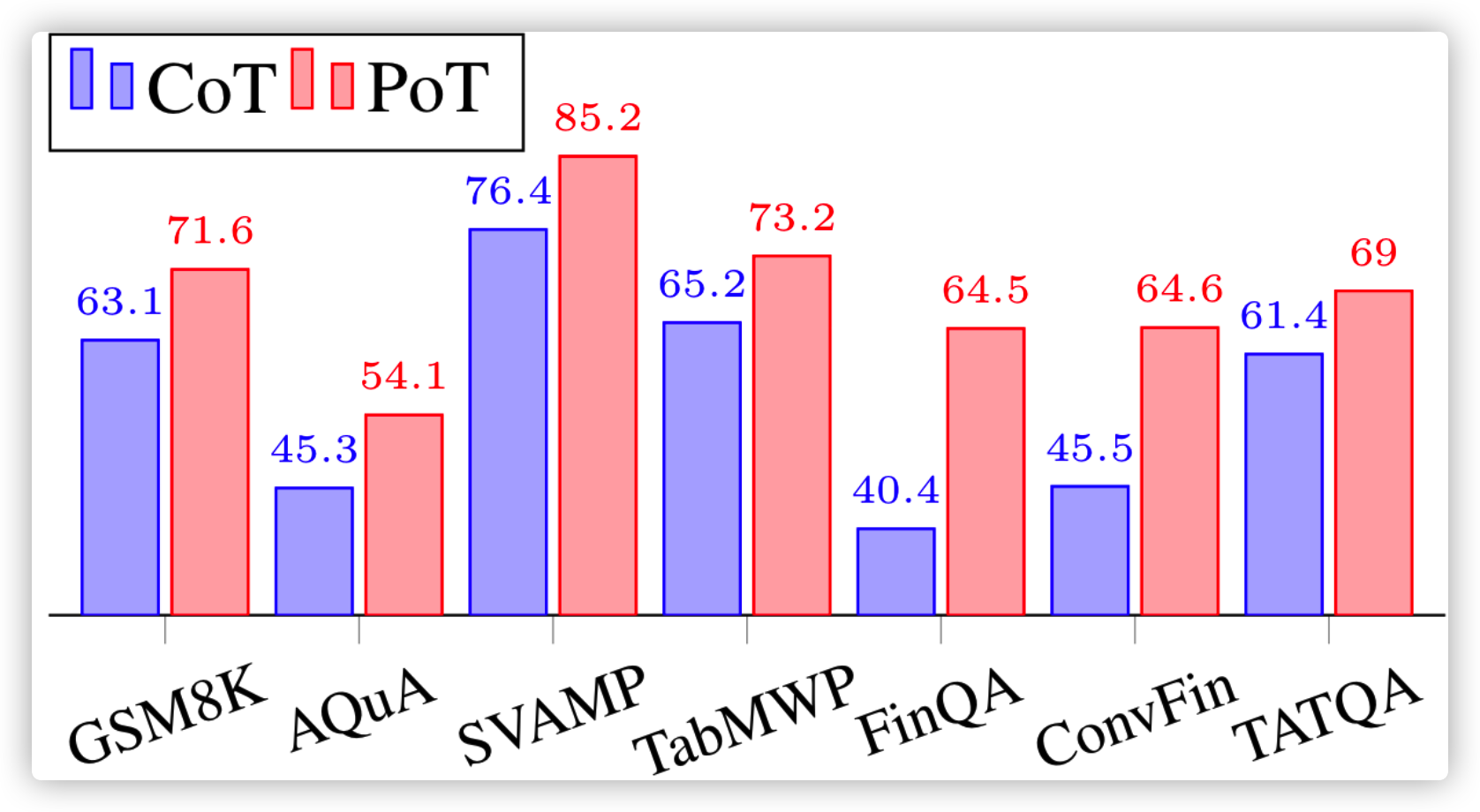
Program of Thought 是不同于 CoT 的工作,出发点也很简单,比较复杂的数值推理任务,靠一步步推理,其实 LLM 还是会搞错
那就有人想了,能不能不让 LLM 来计算,让 LLM 学会调用 Python 程序来搞呢?程序计算肯定比 LLM 自己来靠谱,这就是 PoT 干的事情:

效果也是会比 CoT 好上一些,下图是 Few-Shot 的结果:
Majority Voting
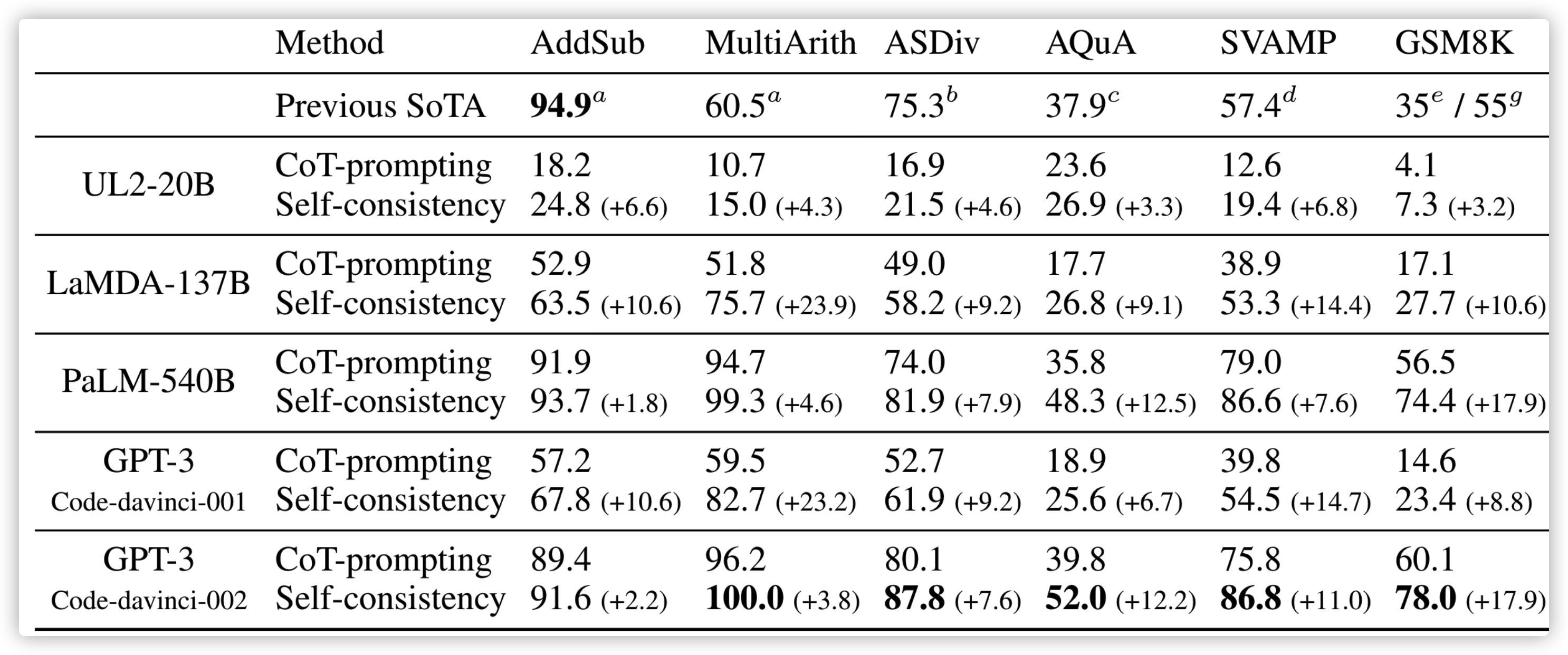
多数投票法(或称之为 self-consistency)是在 CoT 的基础上,对结果进行投票,在推理时,我们采样多个可能的解决方案,然后看最后那个预测结果出现最多,就选哪个

结果也是比较显著的,比单独的 CoT 要好:
Work Memory
Galactica 提出了「工作记忆」的概念,先引入人类思考的习惯,当我让你求几个数字的平均值时,比如 43, 29, 51, 13,你会写一些过程在纸上,这种写出来的称之为 External Work Memory,即为外在工作记忆

仔细看图中倒数两行的位置,有个 thinking,有些人算 136/4 是可以在脑中完成计算的,这种被称为 Internal Work Memory,而 Galatica 正是将两种记忆方式结合在一起解决问题。让我们看个 Work Memory 的例子:

有人说,乍一看,这不就是 CoT 吗?一步步展开思考,没毛病吧,但你看 calculate 那里,这个过程是可以不需要 LLM 自己得出答案的,它可以只写个代码让计算机执行 Python 程序,而 LLM 做的是下达指令,读取输出即可
具体而言,它跟 CoT 的区别或者说 CoT 的不足之处在于:
CoT 相当于上面求平均值一直写在纸上的过程,但是有些 low-level 的思考人类是不需要写下来的,而 LLM 做不到这一点,这也是为什么 CoT 会产生看似正确但又模糊的答案,而 Work Memory 是将 internal 的思考交由更准确的工具去做,比如上述算力大小的例子,写程序,然后执行代码,最后 LLM 只需要读取就行了
这个方法的难点在于数据集的准备,而 Galatica 是通过以下方法来创建:
- 通过程序来控制一些变量,来生成例子(OneSmallStep)
- 从现成的数据集中拿(Workout, Khan Problems)
- 另一种就是直接用<work>这种模版转换(GSM8k train)
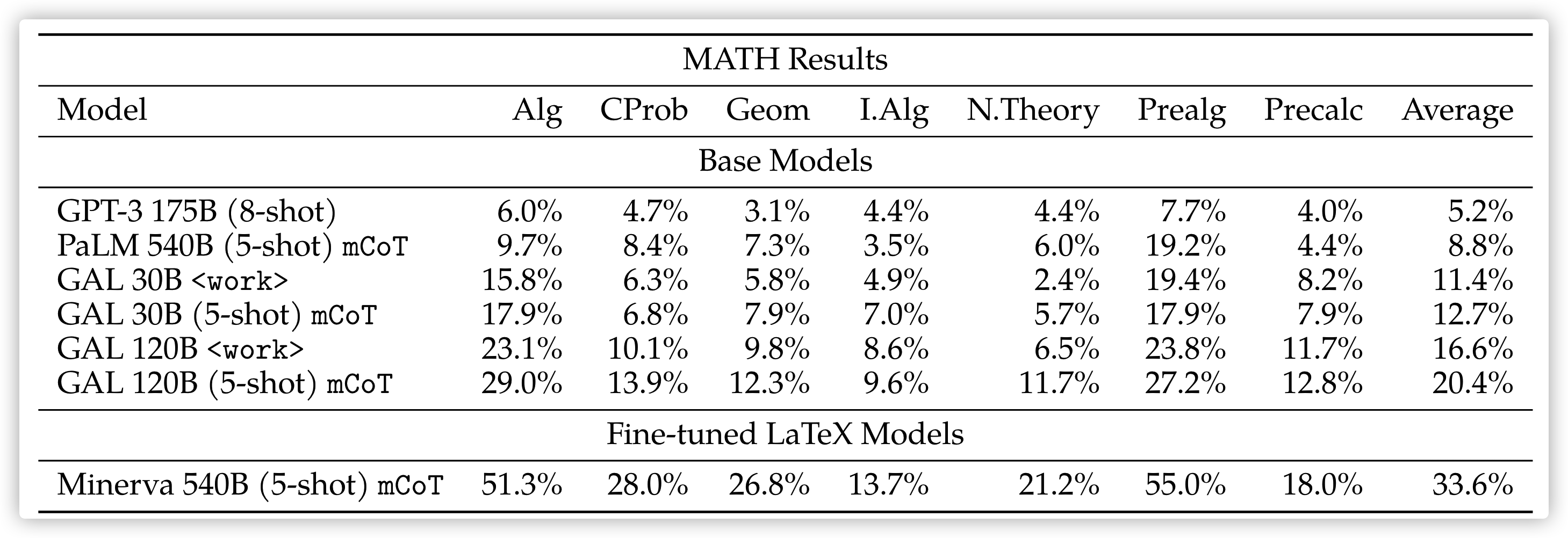
mCoT 即代表 Majority Voting + CoT 一起的,可以看到 mCoT 还是效果优于工作记忆的,不过工作记忆并没有经过很好的养成,数据集既不大也不多样,后面可以优化的空间肯定更多
需要注意的是,不能单纯的拿<work>和 mCoT 对比,因为上面 Galatica 的 prompt 数据集是预训练过的
OPRO
这篇文章我也比较喜欢,目前 LLM 对于 prompt 不稳定,我猜测可能是不一致的原因:用人工优化的 prompt 来调整 LLM 内在输出分布,那很自然就有一个想法,能不能让 LLM 自己来优化使用的 prompt 呢?
这就是 OPRO 做的事情,将 LLM 当做是优化器,不同于以往传统的优化任务,有各种公式做约束,OPRO 是用「自然语言描述」做约束,比如 Find the most effective prompt for this problem,具体框架如下:
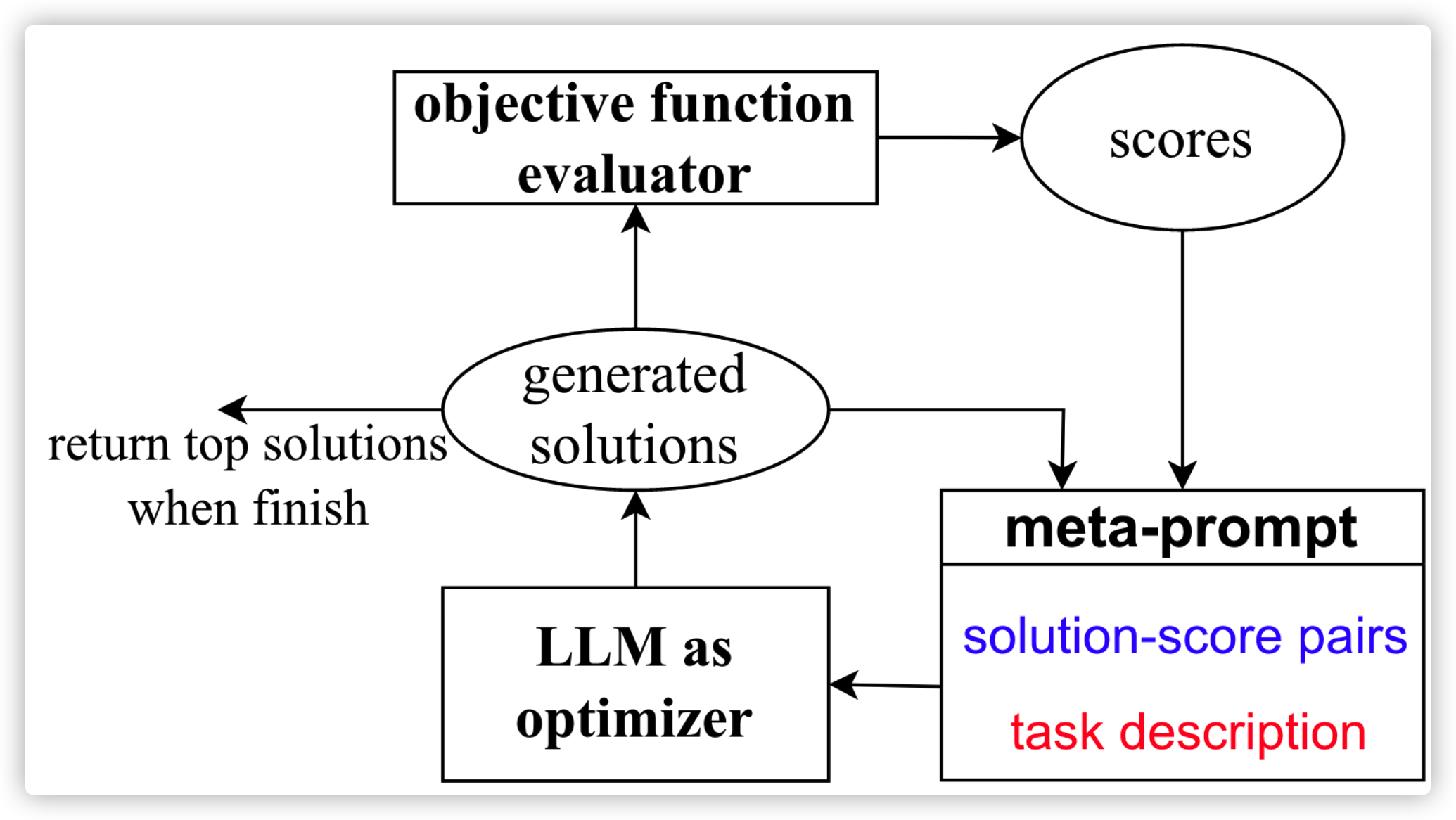
首先是用最开始 prompt,接着让负责优化 LLM 产生出多个 prompt,再根据目标用 负责打分 LLM 进行打分,将打分后的 prompt 和分数一起放进下一次优化中,最后输出分数最高的 prompt

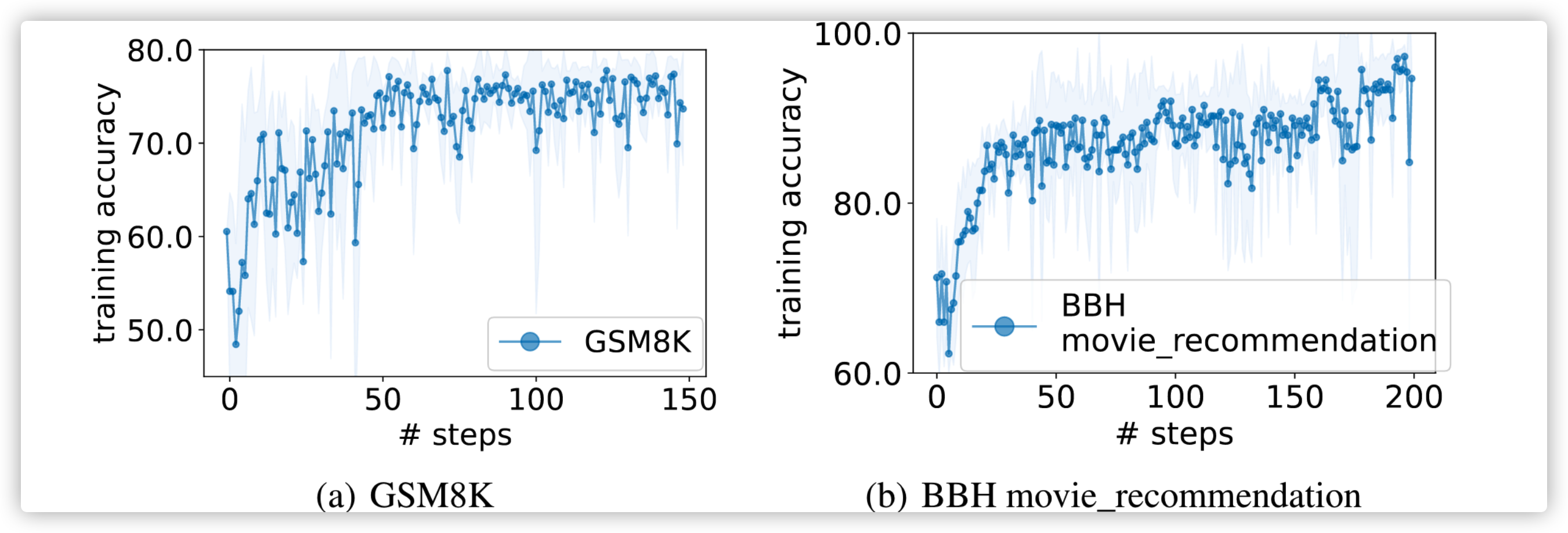
下图是 GMS8k 在优化 prompt 过程中的准确度,这里图可能有误解,其实没有 train,只是在优化过程中找到 prompt,然后在 eval set 进行评测准确率
Reward Models
第二条路线是改进 RLHF(Reinforcement Learning from Human Feedback)
Process Supervision
We’ve trained a model to achieve a new state-of-the-art in mathematical problem solving by rewarding each correct step of reasoning (“process supervision”) instead of simply rewarding the correct final answer (“outcome supervision”).
目前的奖励模型大多基于「结果监督」,追求让模型产出正确的结果,而这样的弊端在于两点:
- 模型中间的思考过程是未知的,解释性和可靠性不高
- 无法真正实现 alignment with humans,只是去对齐结果
In addition to boosting performance relative to outcome supervision, process supervision also has an important alignment benefit: it directly trains the model to produce a chain-of-thought that is endorsed by humans.
那么 OpenAI 的解决方案即引入「过程监督」,让模型每一步思考都和人类的进行对齐,这样就可以较好地解决以上的两个问题。作者还发现,尽管是过程监督,但只对比结果依然比结果监督要好
同时 OpenAI 开源了过程监督的数据集 PRM800K,下图中 ORM 代表「Outcome Rewarded Model」,PRM 代表「Process Rewarded Model」
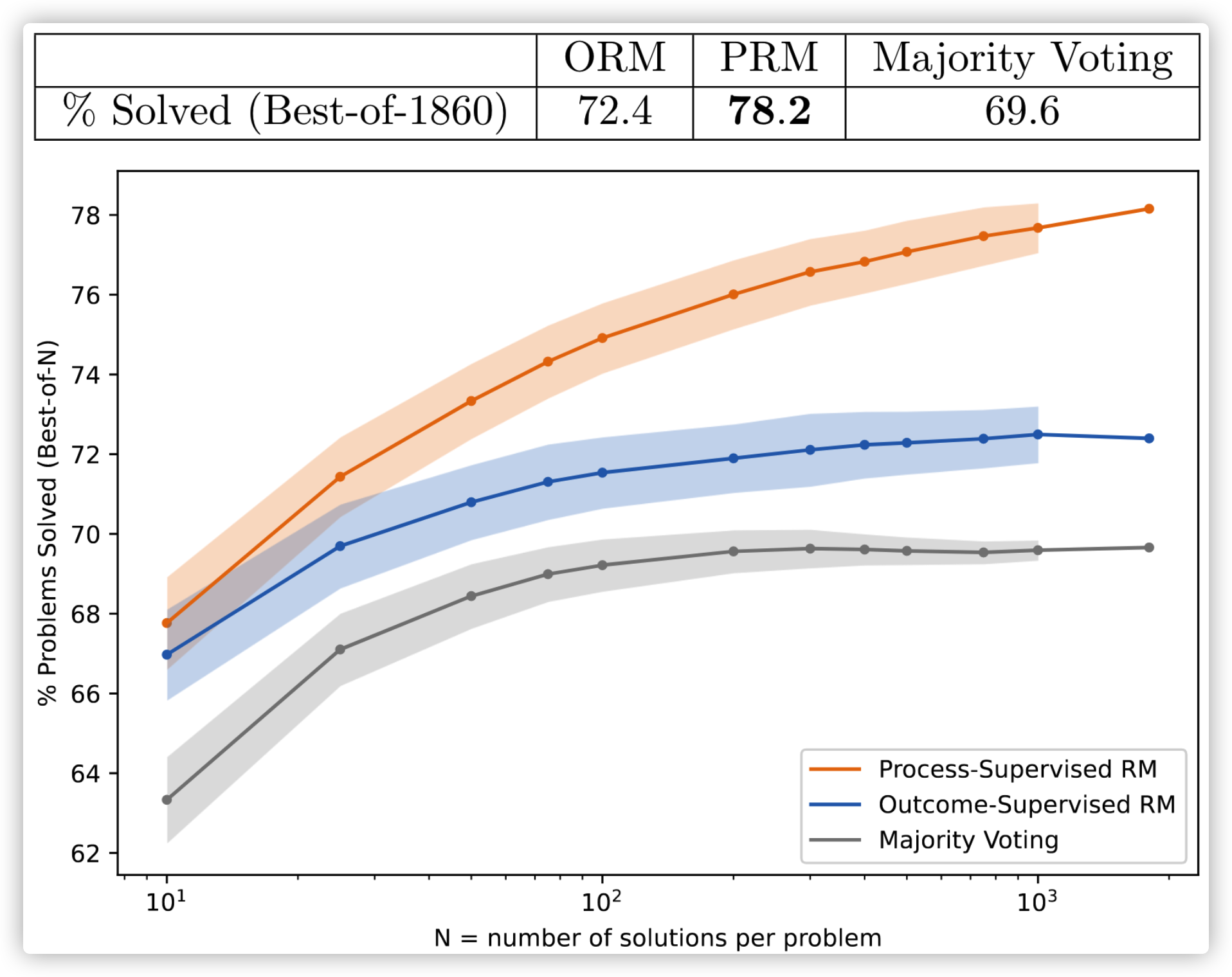
当问题越复杂时,过程监督的优点就逐渐显露出来,结果好的同时更具解释性,可谓是一举两得
Reinforcement Learning from Evol-Instruct Feedback
Reinforcement Learning from Evol-Instruct Feedback(RLEIF)是 WizardMath 提出的技术,设计比较巧妙,很 nice 的工作,一共分为三步:
第一步:是先用指令微调获得模型 Wizard-E
第二步:接着模仿 Evol-Instruct 利用 Wizard-E 和 ChatGPT 来扩充训练集,主要是分为两个方面,让问题变得更简单(Downward)和让问题更复杂(Upward),比如加更多限制,复杂化原来的问题。然后用 Wizard-E 进行排序,获得训练 Instruction Reward Model(IRM)的数据集
再让 Wizard-E 模型来生成解决问题的步骤,用 ChatGPT 来评判每步的正确性,以此来生成训练 Process Supervision 的数据集
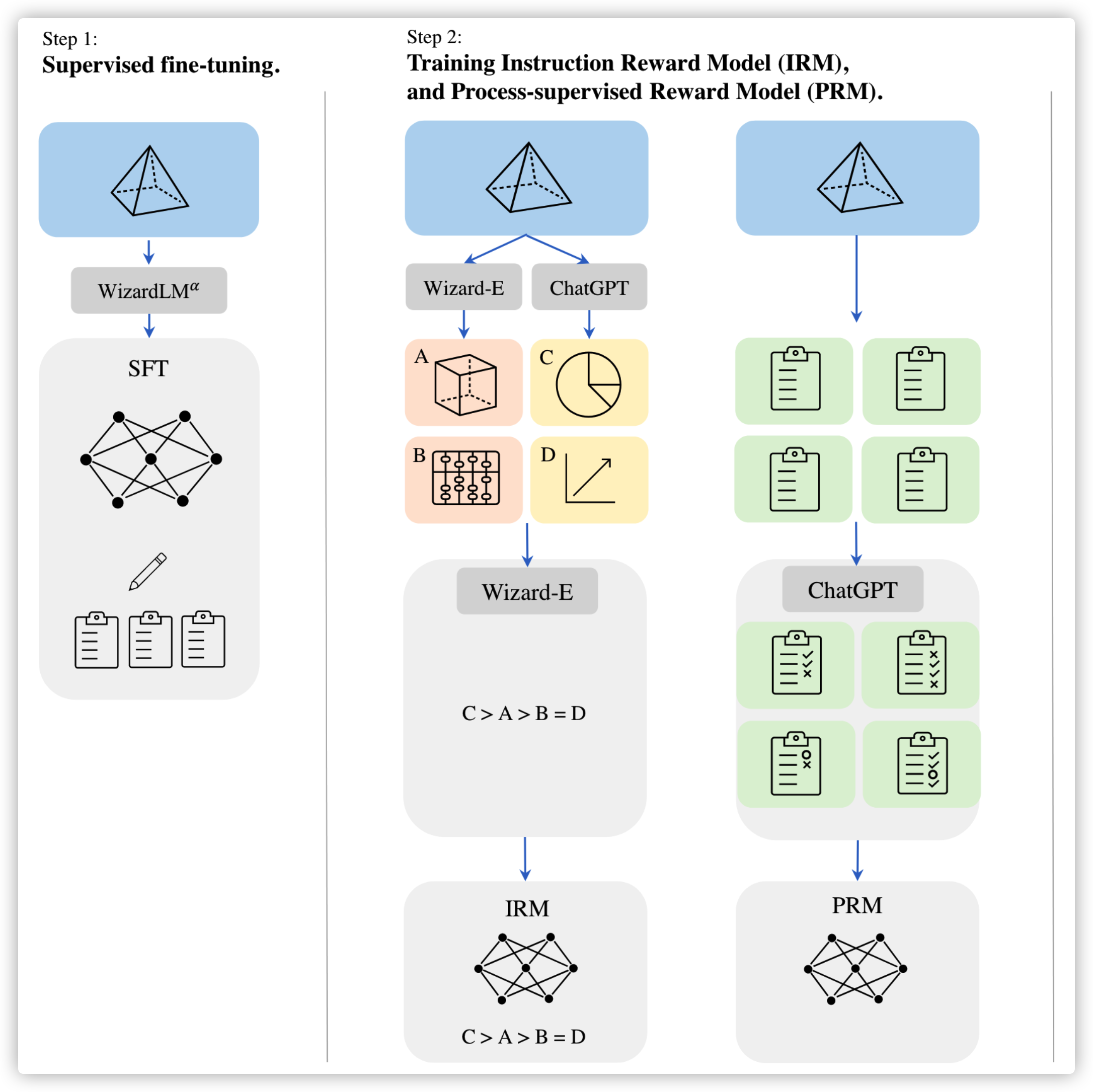
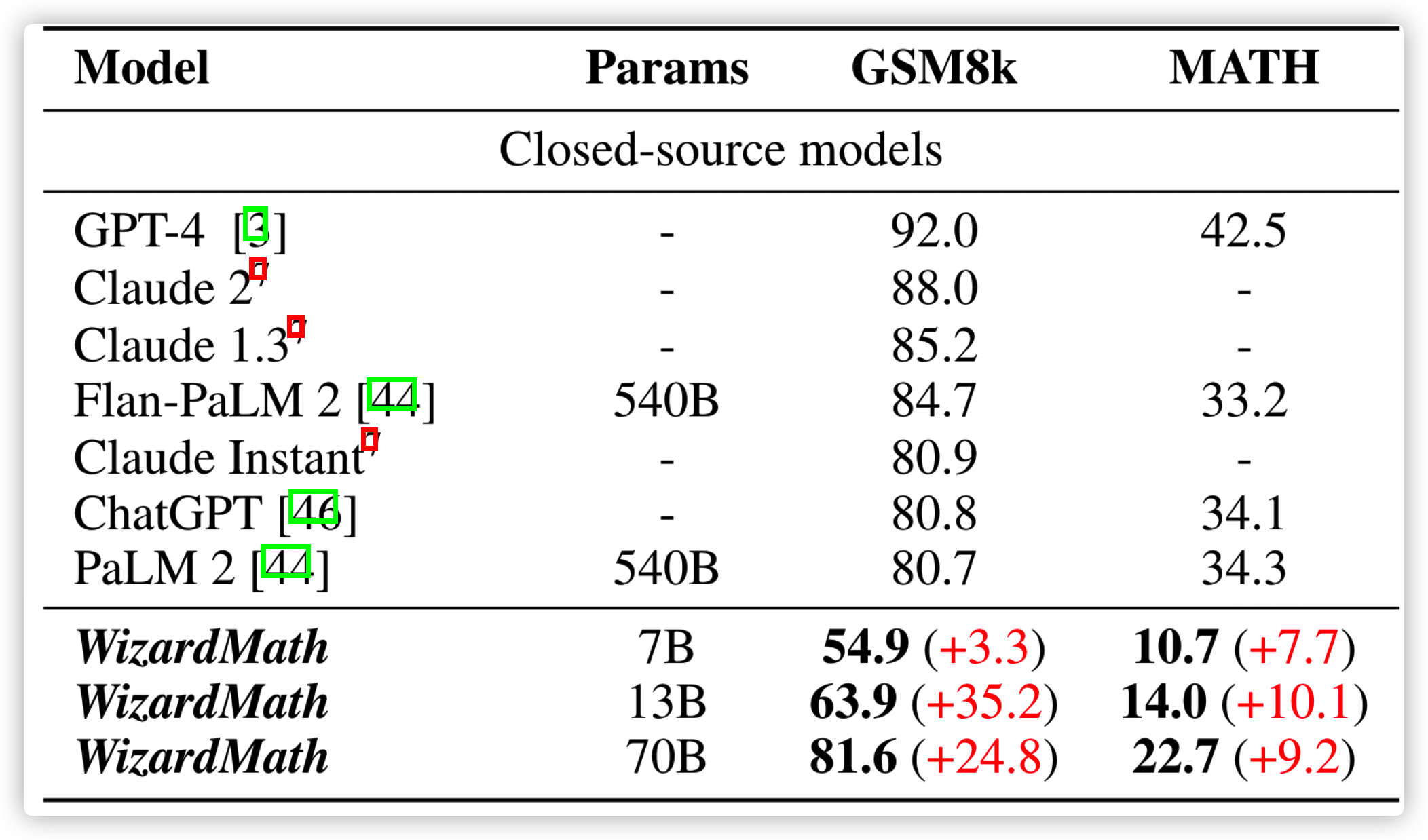
第三步便是用 PPO 联合训练两个奖励模型,具体是将两个获得的奖励相乘,模型的效果也是比较惊艳的,不过在 MATH 数据集上还差点意思(可能是参数规模不够)
数据入手
Galactica
Galactica 用于预训练的数据量比同等大模型用的要小得多,整个数据集是经过清洗的「科学领域」数据集,包括论文,参考资料,蛋白质序列,化学公式等等,大小为仅有 106 billion tokens
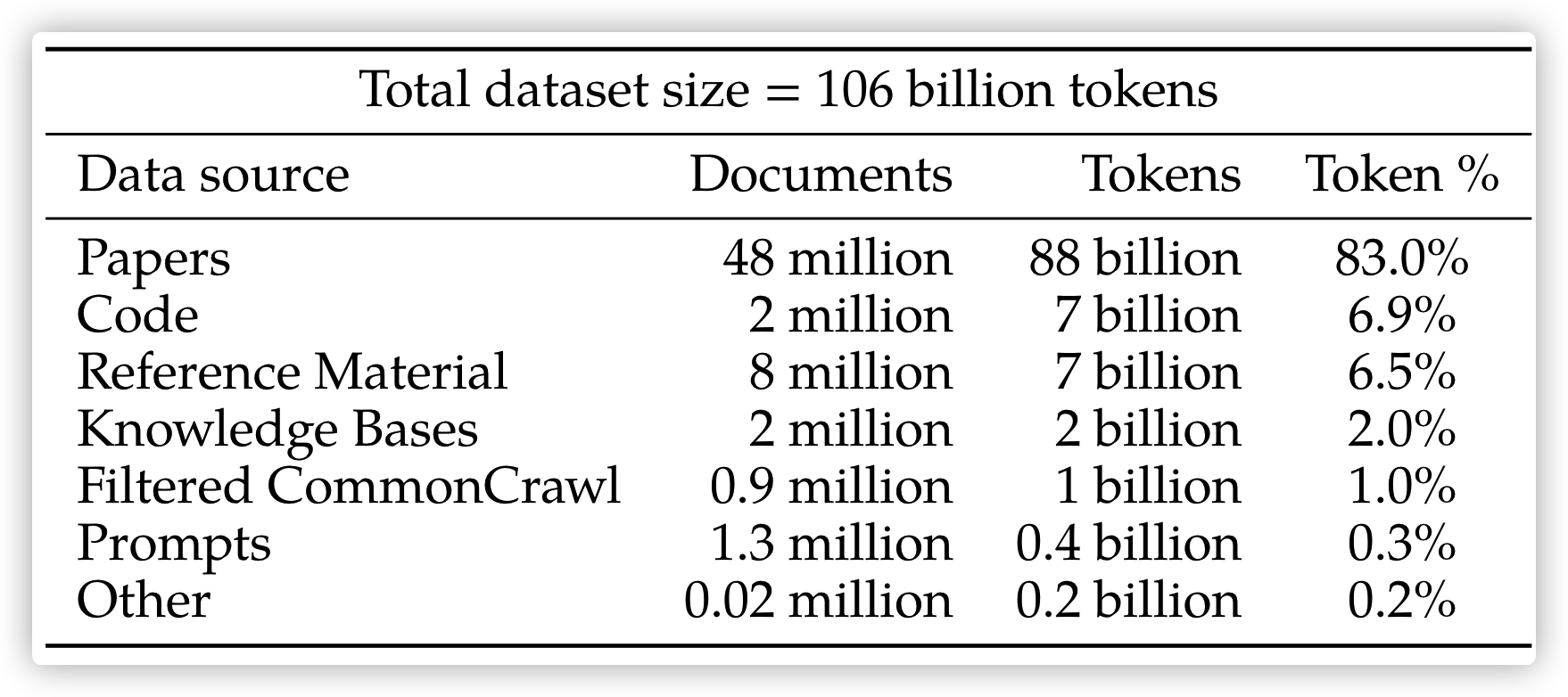
从上述表格可以看出,论文占了大头(83%),令人惊讶的是 CommonCrawl 仅仅占了 1%
还将prompt数据集加入了预训练之中

作者还提到 prompt prertraining 可以增强模型 general 的能力:
Minerva
无独有偶,Minerva 同样收集了来自 arxiv 上的论文,有趣的是 General 的语料也是占比很少
另外还收集了带有数学公式的网站:

不一样的是利用方式,Minerva 采用的模型基座是 PaLM,然后在收集的数据上进行 Auto-regressive loss 微调
Rejection Sampling FineTuning
上面的 Galatica 和 Minvera 都是收集数据,是否可以让 LLM 生成数据呢?
RFT(Rejection Sampling FineTuning)是阿里的工作,方法比较符合直觉,直接让微调后的模型来生成不同的例子用以扩充数据集,然后根据一些准则来筛选:
- 答案不对的
- 计算结果和 Python 结果不一致的
可以看到效果比单纯的 SFT 要好上不少:

AugGSM8K
还是那句话,我们可以用 LLM 来进行数据的扩充,问题是怎么扩充呢?这篇工作针对问题和回复分别进行了增强:
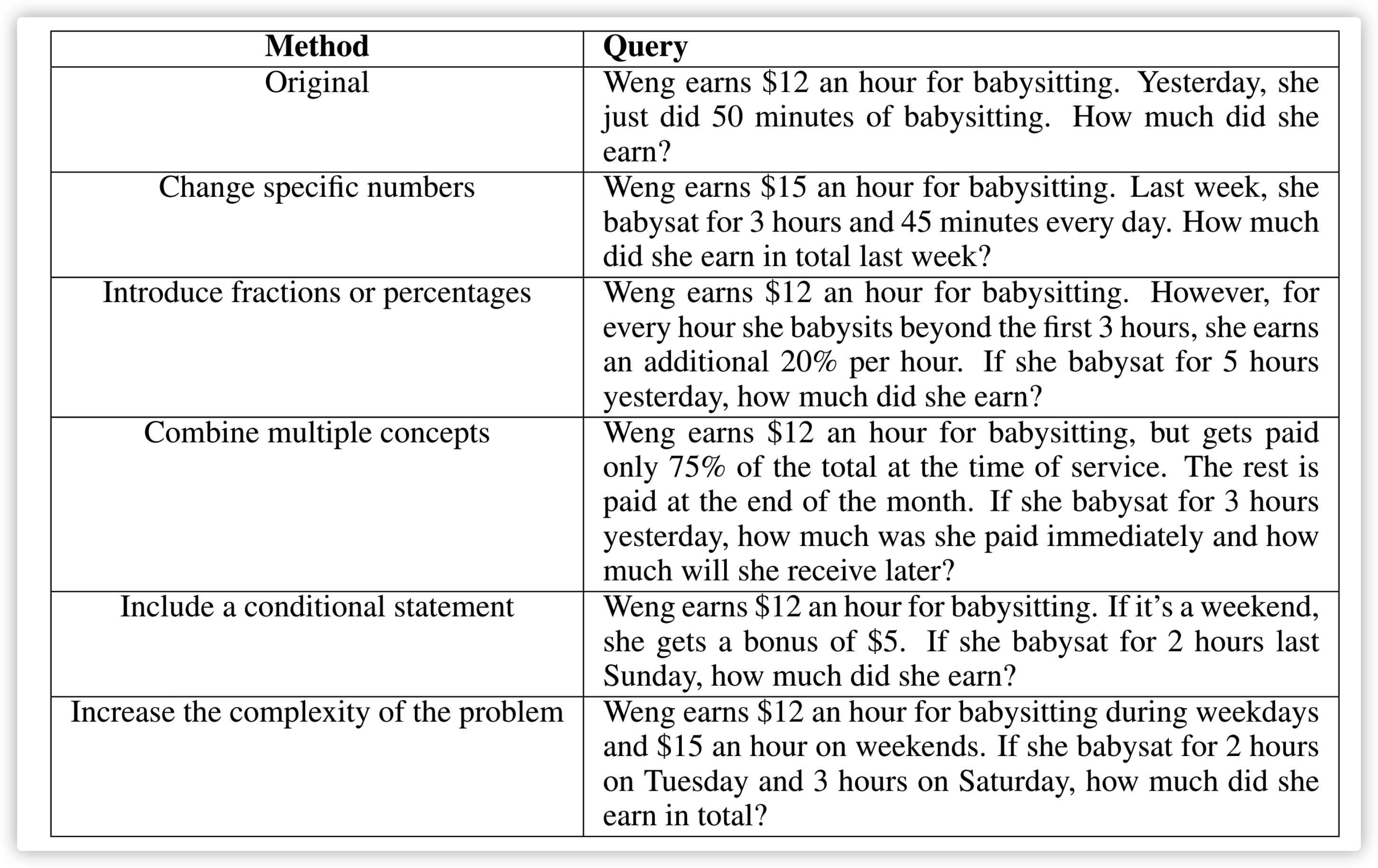
关于问题,分别采用了五种增强策略(见下图左列),这些原则的设计还是比较符合直觉的
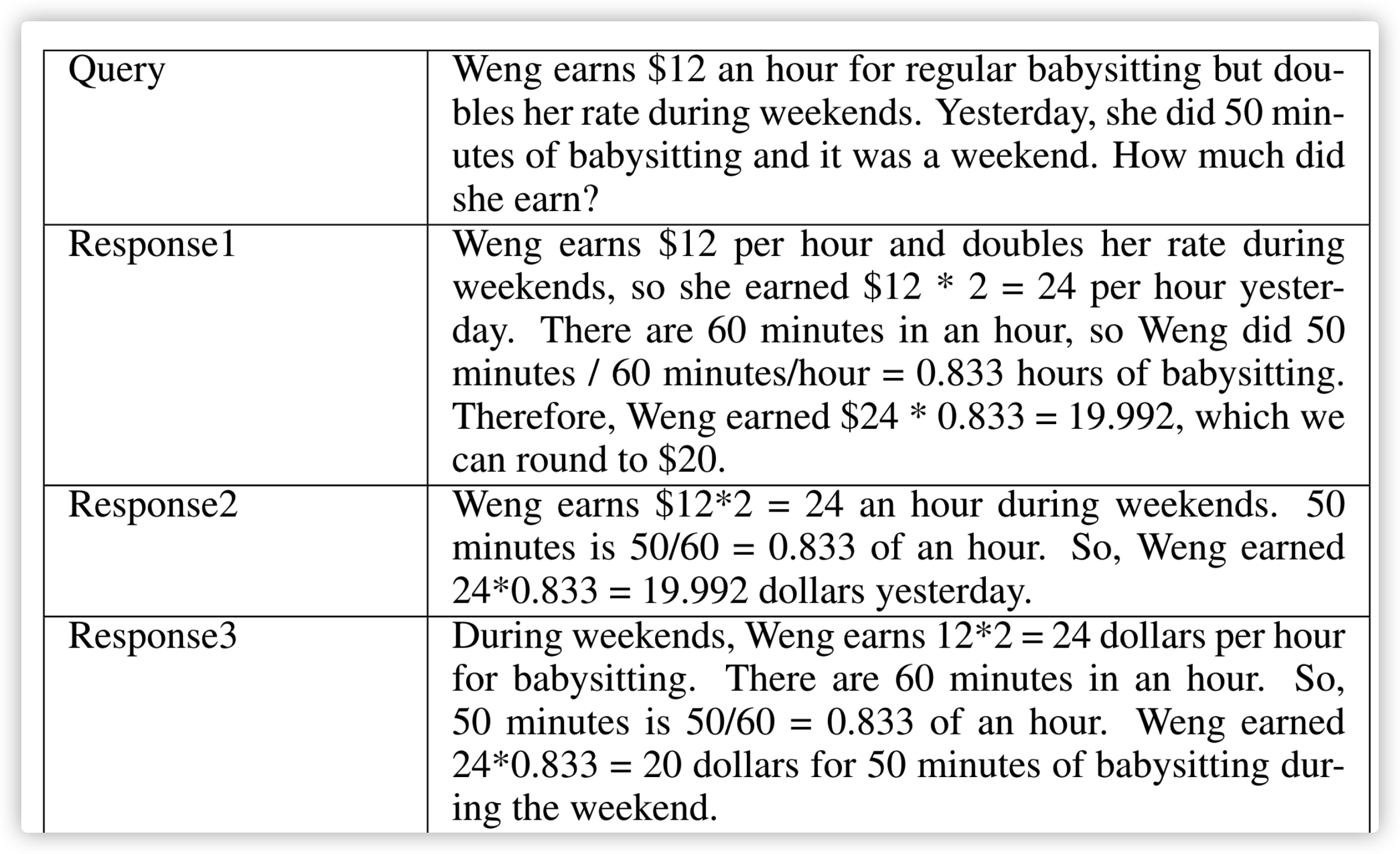
对于回复,作者是采用不同的温度来生成多样化的推理路径,当然也会对于明显错误的进行过滤
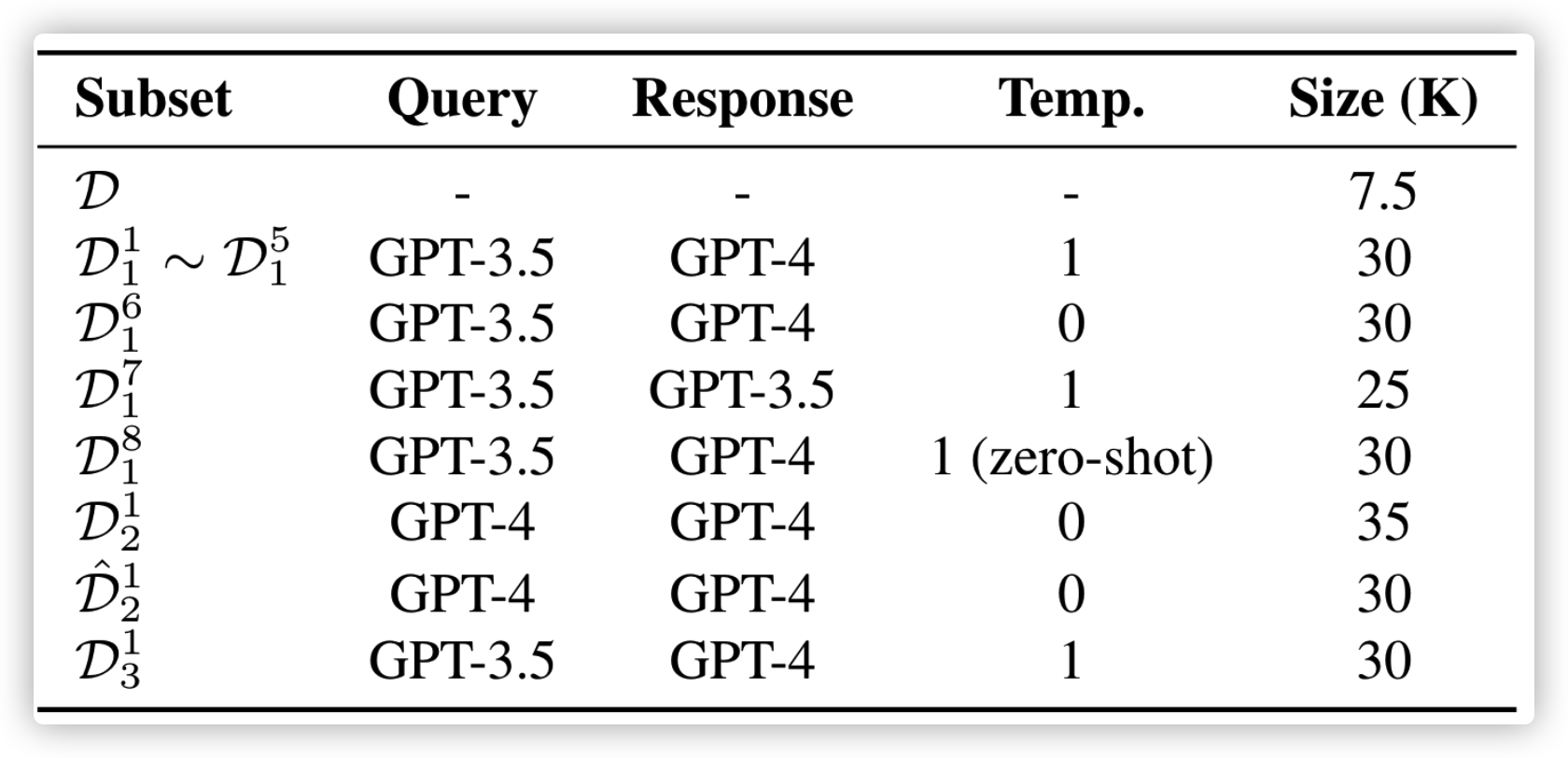
数据集概览如下:
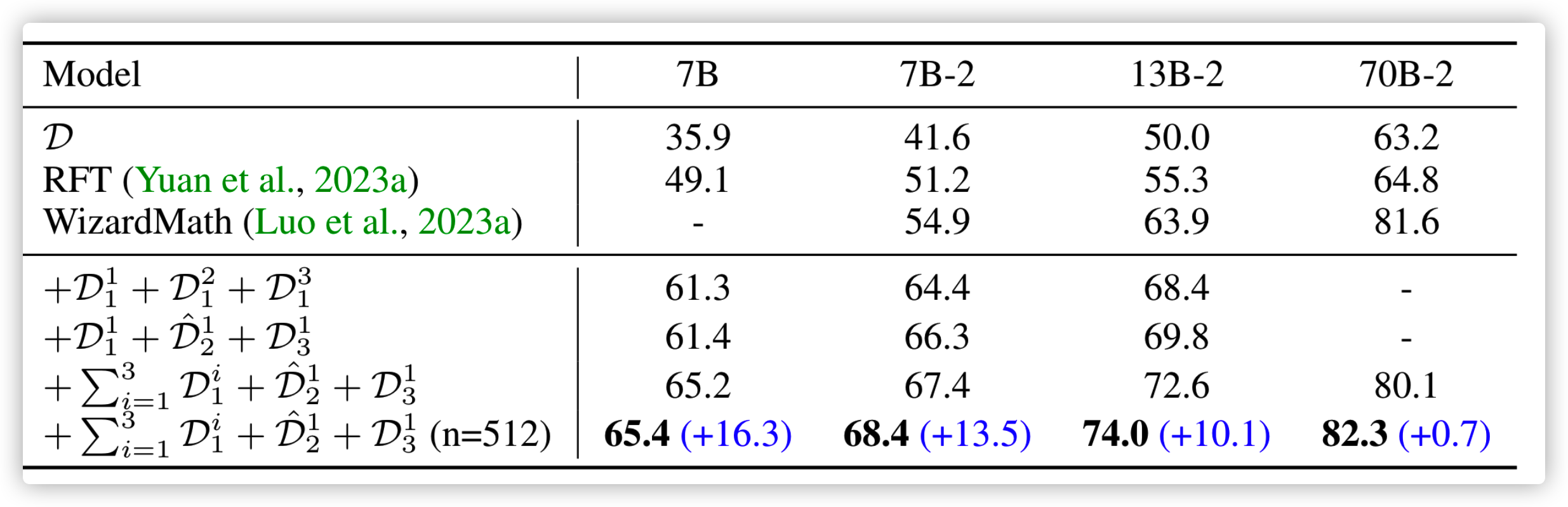
生成的数据集证明也是有效果的:
MetaMath
这篇文章跟上面的 AugGSM8K 算是同期工作,也是利用 LLM 来对数据集进行增广,然后进行微调
它主要是对问题进行增广,分为以下几种:
- Rephrase Question
- Self-Verification
- FORBAR

效果的话基本和 AugGSM8K 也差不多,除了 70B 是 QLoRA,其他的参数是 LLaMA 的
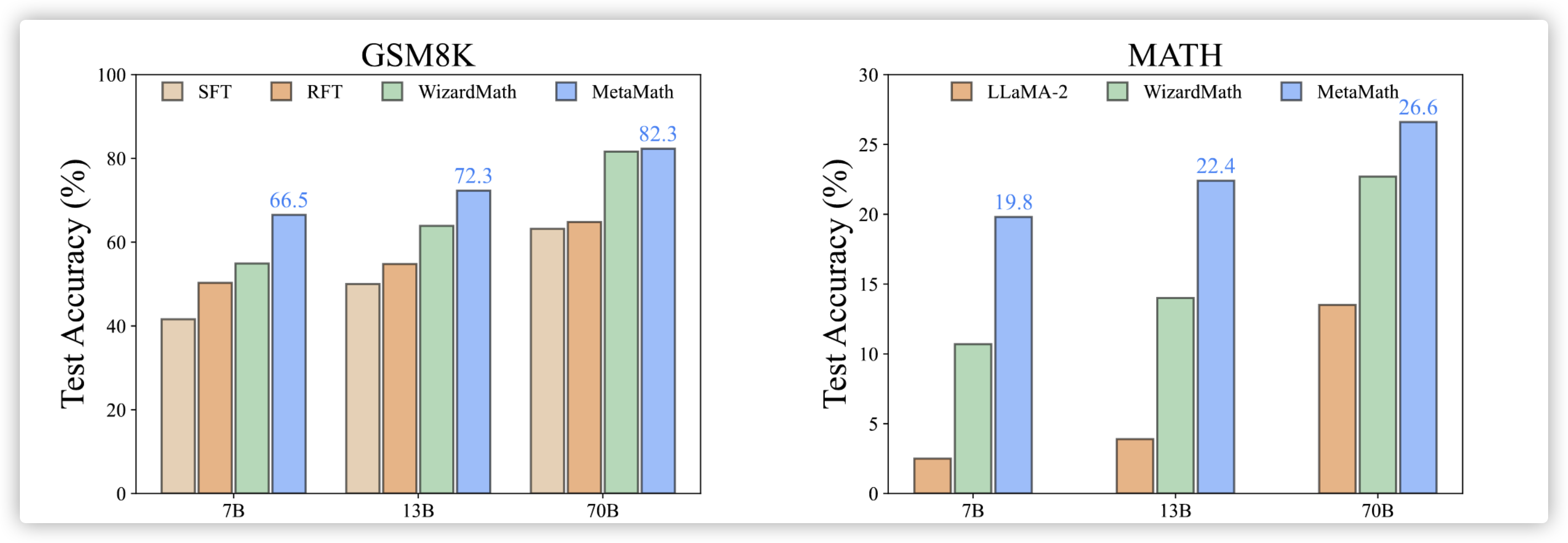
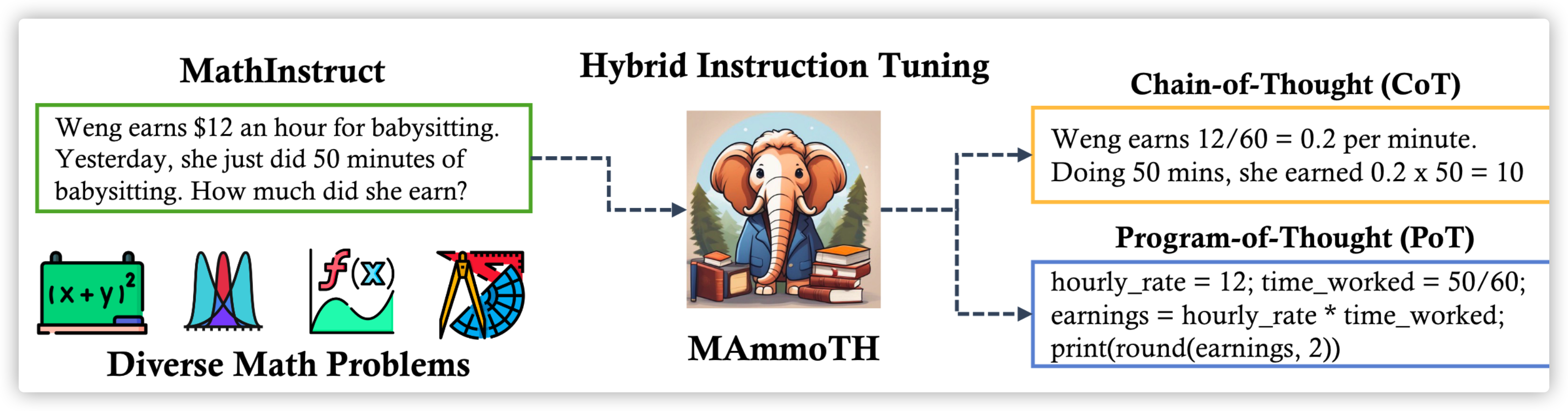
MAmmoTH
这篇工作是我数据分支线中很喜欢的一篇,其实 RFT 类通过 Bootstrap 来搞数据集的路子,会丧失「通用性」,在 GMS8K 上效果好,而在 MMLU-Math 上就有可能掉很多点;而 Galatica 和 Minvera 付出的代价要很多
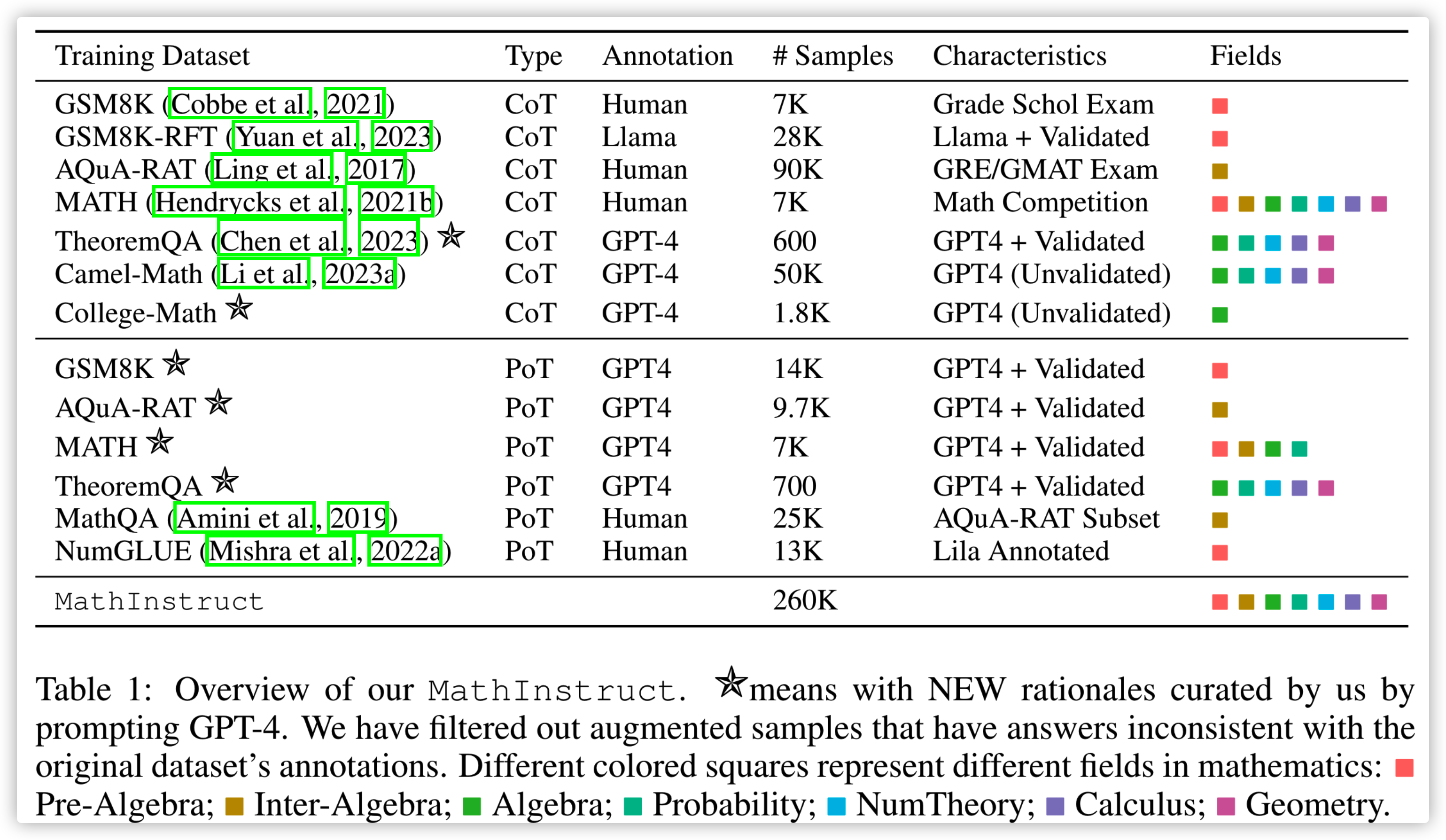
那么 MAmmoTH 就构建了一个数据集:MathInstruct:
下图是其与其他数据集的对比:
特点有三个:
- 量大,一共有 200K
- 覆盖比较多的数学领域
- Prompt 同时包括了 CoT 和 PoT
其实有些时候我觉得搞数据集是在水文章,但是有些时候是真的很有意义,比如 ImageNet,以及这一篇工作,方法再 fancy,数据缺少带来的问题是很难解决的
效果也很顶,比 RFT 以及 Wizard 更具备通用性,是 Llama 就能有如此效果,相信换更大的模型肯定会有不错的提升
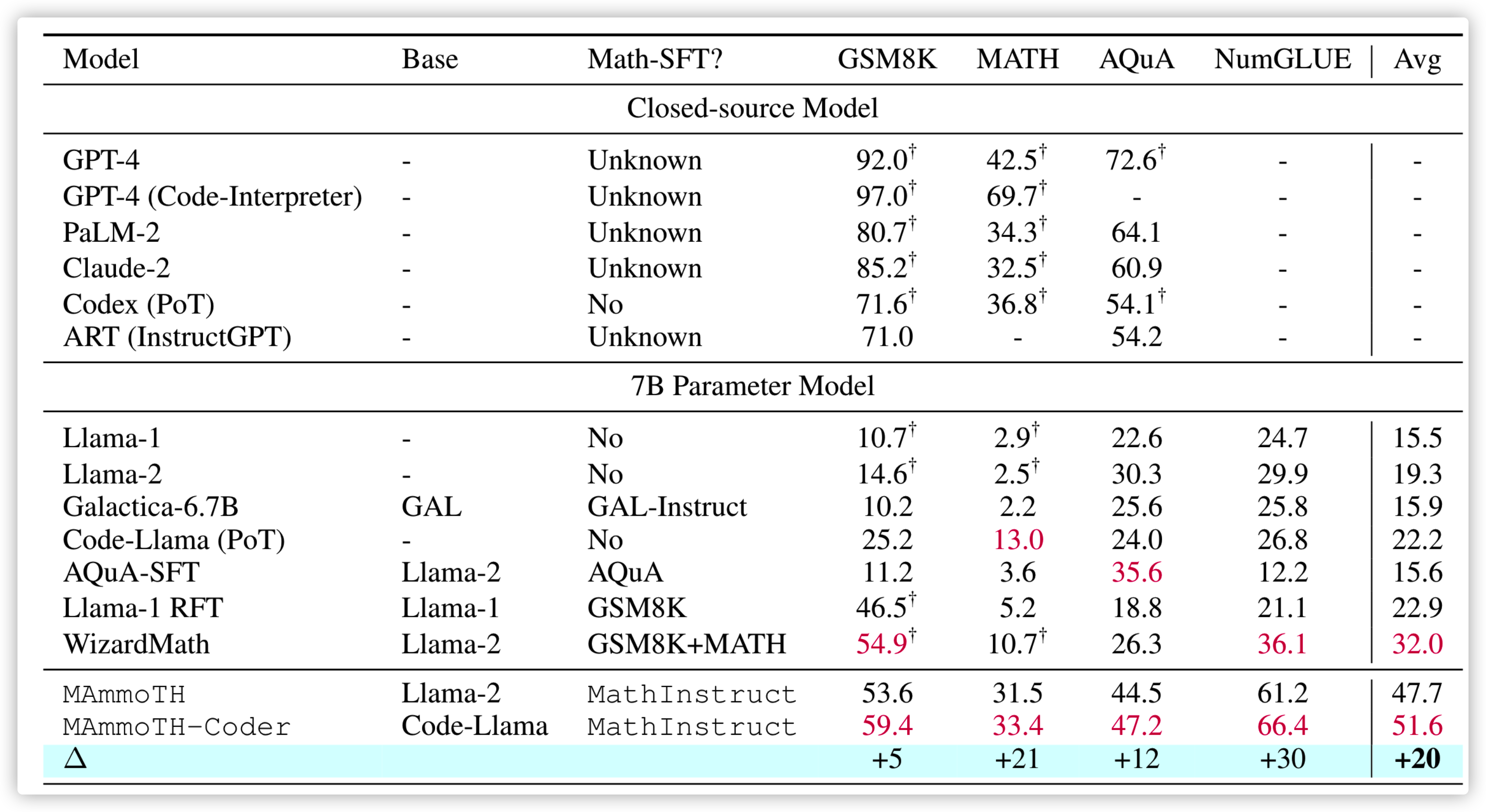
架构
MathGLM
具备算数能力
这篇工作是相当有趣,它也解决了我的困惑,若 LLM 从一开始就学数值推理,能不能做好?同时,这篇工作给了一个全新的视角来做一个「专家模型」
首先是其数据构造环节,很有启发性,无论是 CoT,还是工作区记忆,都强调需要把细节尽可能写下来,LLM 不能像人一样跳跃,这篇工作直接将推理的结果改成一步步得出

接下来选用的主力 backbone 是 2B 的 Transformer-Decoder,你没有看错,这篇文章并没有使用 LLM Backbone,而是用 AutoRegressive loss 直接用上面数据集去训练
下图的测试例子一共有 9592 条,直接碾压 GPT-4。当然,我认为这里的是裸模型,没加任何操作,如果用好的操作,GPT-4 应该可以做得更好。因为你拿一个垂域和一个通用模型比,至少也应该给 GPT-4 一些更好的 Prompt Method,或者一些上下文学习的例子
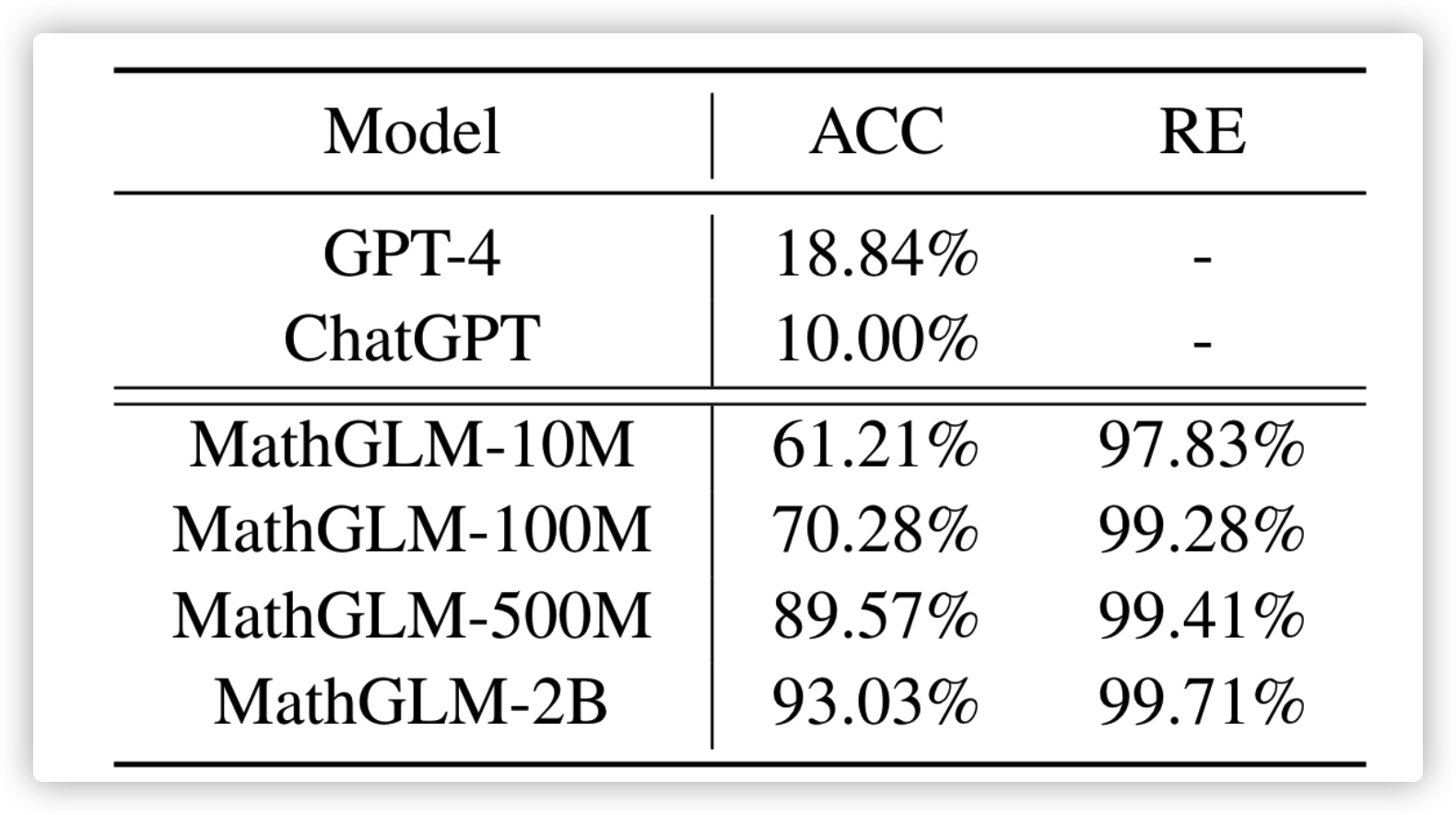
不过这个实验结果证明了以下两点:
- Decoder-Only 架构的确可以学习到算数规则
- 参数的规模不需要那么大,2B 就能有很好的能力
通用一点的专家模型
为了让 MathGLM 可以解决文本描述的问题,MathGLM 还需要变得更通用,于是把目光放到了带有描述的数据集,同样的,将原来的解题步骤进行了细化,这样的好处是,既可以学习到数学知识,又可以建模文本,相当于比之前的专家模型更具通用性

路在何方
那么理想化 LLM 能解决数学问题的标准是什么呢?
- 题目的解答得正确
- 解题过程正确可解释
这两点是有可能做到的。综合以上的论文,我大胆预测一下未来的 Math LLM 可能的发展趋势,思路肯定是做一个较为通用的「专家模型」,具体怎么做呢?
数据的收集和处理
数据的收集前面的工作可谓是百花齐放,核心思路就三个:
- 尽可能人工去搞高质量的数学推理数据集,你像 LLM 在文本领域能成功,肯定离不开大量的高质量数据集
- 如果特别强领域特性的没有,就找更接近的,比如论文这种科学领域的语料
- 实在不行,就想办法让 LLM 来自我产生数据集(Bootstrap),但这种很依赖于模型,且会引入模型的内在 Bias,但不失为提升模型的手段
数据的处理这块看着比较简单,其实不然
举个例子,MetaMath 就将答案改写成一步步过程,引入第一个数据原则:detailed,把 LLM 当成弱智,越详细越好
第二个是 Minerva 的处理,它将公式单独处理成 LaTeX 中见到的样子,就相当于你用特殊的 token 来包裹公式,用某种方式来提示 LLM,第二个原则:保留不同于文本的模态特征
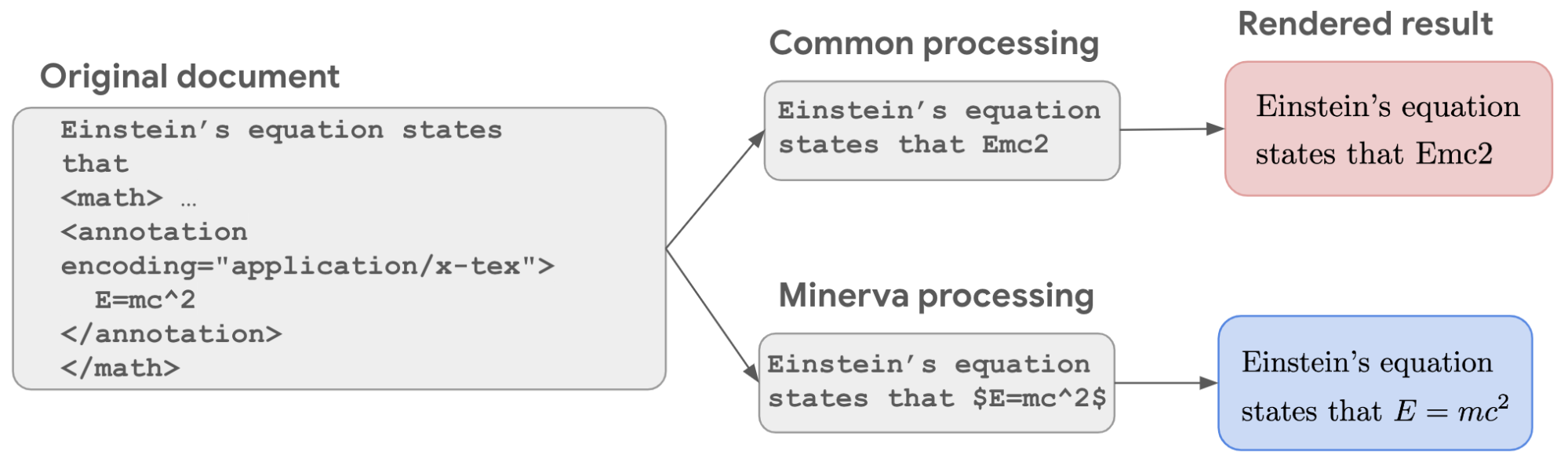
专家模型的路线
这一点其实 MathGLM 和 Galatica 给了我不少启发,但目前有一个问题尚未解决:
如果先预训练 Math LLM,后期去建模文本,究竟能保留多少通用性,或者反过来,如何保留数学的能力,说到底就是 how to be general and specific,如何衡量「通用性」和「专用型」,是值得考量的
决定之后,其实就可以借鉴这两个模型的路子,比如将 Prompt 数据集直接放入预训练中,以及用 AutoRegressive loss 去建模数值推理的例子等
预训练完毕,再利用 SFT 或是 RLHF 类方法去进一步微调
参数的规模我觉得应该不会需要很大,相反,对于数据如何利用是值得考量的,正如在 Galatica 中提到的:作者们发现当重复训练时,性能也会稳步上升,作者将此归因于高质量的数据
更强的推理方法
从简单的 Zero-Shot 再到 CoT,到 OPRO,经历了太多 Prompt 方法的变迁,我想未来应该很会有,但趋势应该是如何将 LLM 本身的知识引入其中来选择或构造 Prompt,这种一致性带来的提升会更稳定和持久
最后一个问题
How to leverage LLM’s intrinsic ability to do reasoning?
这也是我最近一直在想的问题,你看在数据那块,你会发现让模型生成一些例子再放进去推理会比直接推理要好一些,这都是模型自己的能力,有没有什么更优雅的方法可以将这种能力抽离出来
换句话说,我们对 LLM 本身能力的压榨是不是还有上升的空间?
References
- https://openai.com/research/improving-mathematical-reasoning-with-process-supervision
- https://galactica.org/static/paper.pdf
- https://arxiv.org/abs/2203.11171
- https://arxiv.org/abs/2201.11903
- https://arxiv.org/abs/2206.14858
- http://arxiv.org/abs/2309.03409
- https://arxiv.org/pdf/2308.09583.pdf
- https://arxiv.org/abs/2304.12244
- http://arxiv.org/abs/2308.01825
- https://arxiv.org/abs/2309.05653
- https://arxiv.org/abs/2211.12588
- http://arxiv.org/abs/2310.05506
- http://arxiv.org/abs/2309.03241
- https://arxiv.org/abs/2309.12284
- https://arxiv.org/abs/2308.07758
- https://arxiv.org/abs/2212.09561