Problems To Solve
- To Scale Down the model size while maintaining the performances.
- To incorporate External Memory Retrieval in the Large Language Model Modeling.
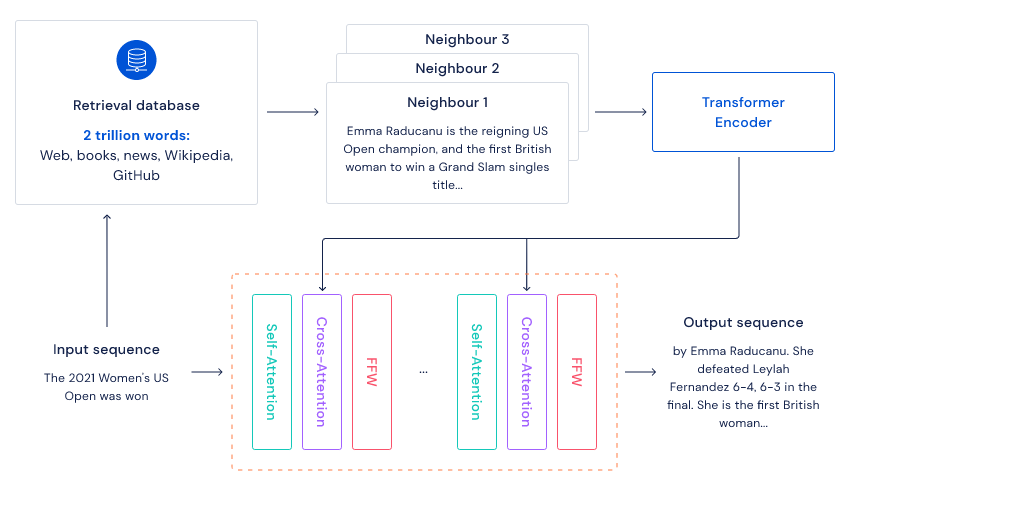
How?
Data Construction
Training & Evaluation set:
- \(\text{MassiveText}\) for both training & retrieval data (contains 5 trillion tokens)

- SentencePiece with a vocabulary of \(128K\) tokens
- During training, we retrieving \(600B\) tokens from the training
- The evaluation contains \(1.75T\) tokens

Test set leakage:
Due to the huge retrieving database, the test set may have appeared in the training set. Thus, the authors apply 13-gram Jaccard Similarity between the training and test documents to filter those training documents similar to the test documents (i.e., the similarity is \(\geq \textbf{0.80}\))
Retrieval Modeling
Key-Value Format of the Database:
- \(\text{Key} \Rightarrow\) frozen BERT Embedding
- \(\text{Value} \Rightarrow\) raw chunks of the tokens
using the SCaNN library
the similarity depends on the \(\text{L2 Distance}\):
$$ ||x-y||_2 = \sqrt{\sum_i (x_i - y_i)^2} $$
pre-compute the frozen BERT Embedding to save the computation and the Embedding is averaged with time.
retrieving targets are the corresponding chunks and their continuation in the orig document
The architecture
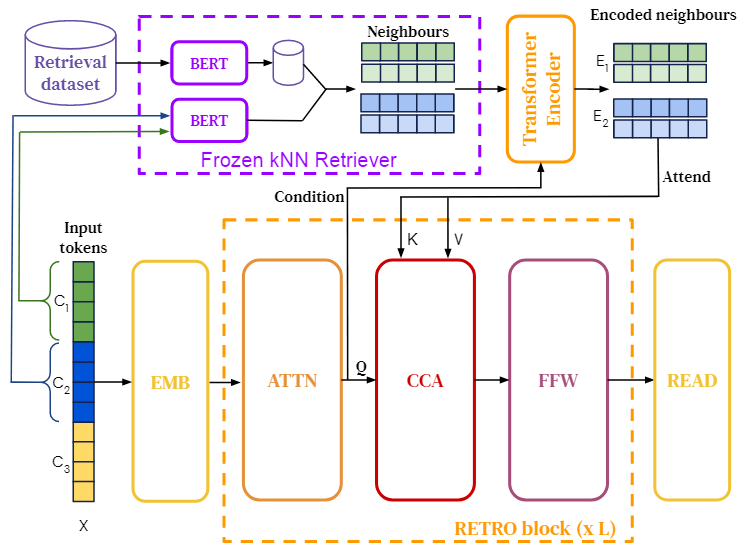
- Assume the input sequence \(\text{X}\) contains \(9\) tokens, it can be split into \(3\) chunks (i.e., \(C_1, C_2, C_3\)) whose sizes are \(3\) respectively.
- Then the chunks are embedded through the frozen BERT embedding. We can retrieve neighbours of those input chunks.
- We also embed the input sequence and then apply self-attention mechanism on them to get the hidden states \(H(X)\)
- Furthermore, we need to encode the neighbours. Here, the transformer encoder is bi-directional. And it outputs the representations of the neighbours by conditioning on the hidden states of the input chunks.
- After we get the representations of the neighbours, we let them attend the input chunks as the \(\text{K and V}\) while the input chunk is \(\text{Q}\). The attending network is called CCA(\(\textbf{C}\)hunked \(\textbf{C}\)ross \(\textbf{A}\)ttention). I introduce it in the following part.
- When the neighbours finish attending the input chunks, the input chunks can be represented by the retrieved neighbours. The representations are going through the FFW(\(\textbf{F}\)eed \(\textbf{F}\)or\(\textbf{W}\)ard). Thus, a Retro-Block contains self-attention mechanism, CCA and FFW.
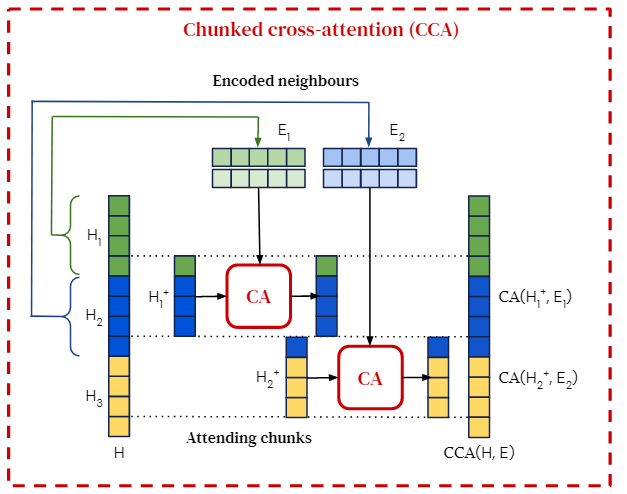
- Take the green chunk as the example, we retrieve its neighbours from the database and we let them attend with the concatenation between the green chunk and its next chunk. To put it more precisely, assume we retrieve the neighbours \(E(mi)\) for the chunk \(m_i\) which contains \(n\) tokens: \({m{i1}, m*{i2}, \dots, m*{in}}\), we concatenate the last token of \(mi\) with the next chunk \(m_j\) except the last token \(\Rightarrow \text{Concatenate}(m{in}, m_{j1, \dots, jn-1})\).
- After the concatenation, we apply CA(\(\textbf{C}\)ross \(\textbf{A}\)ttention). CA is the common attention mechanism.
- Finally, we concatenate the outputs and pad them.
Note, the relative positional encoding is applied.
Experiment
Scaling the Retro
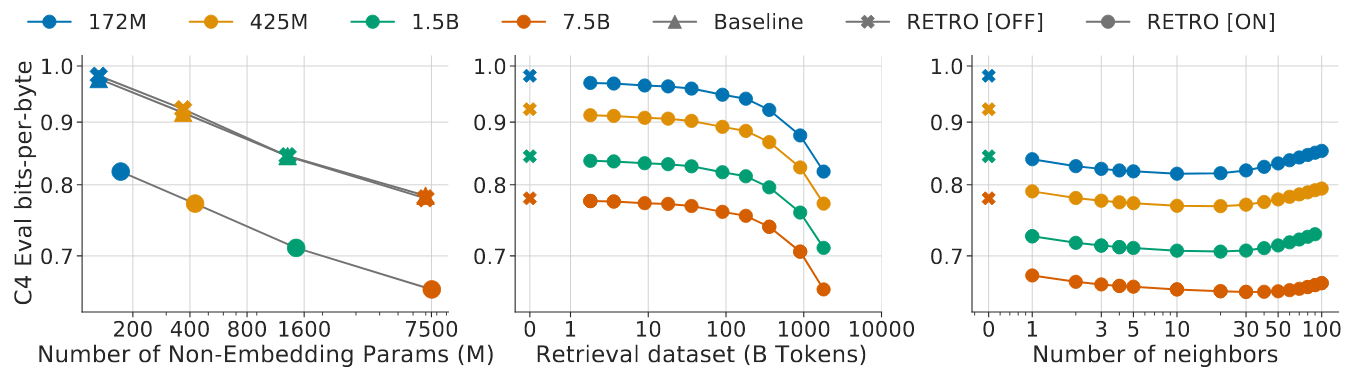
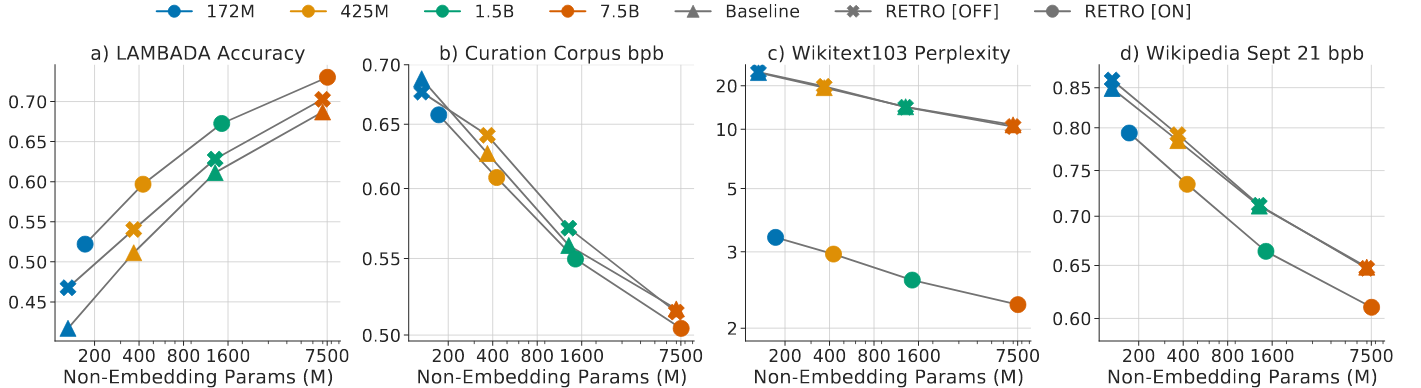
- The scale of the Retro and the retrieved tokens are proportional to the performance.
- The number of neighbours has an upped bound: somewhere near \(40\). Maybe too many neighbours reduce the retrieval quality.
Improvement Comparison
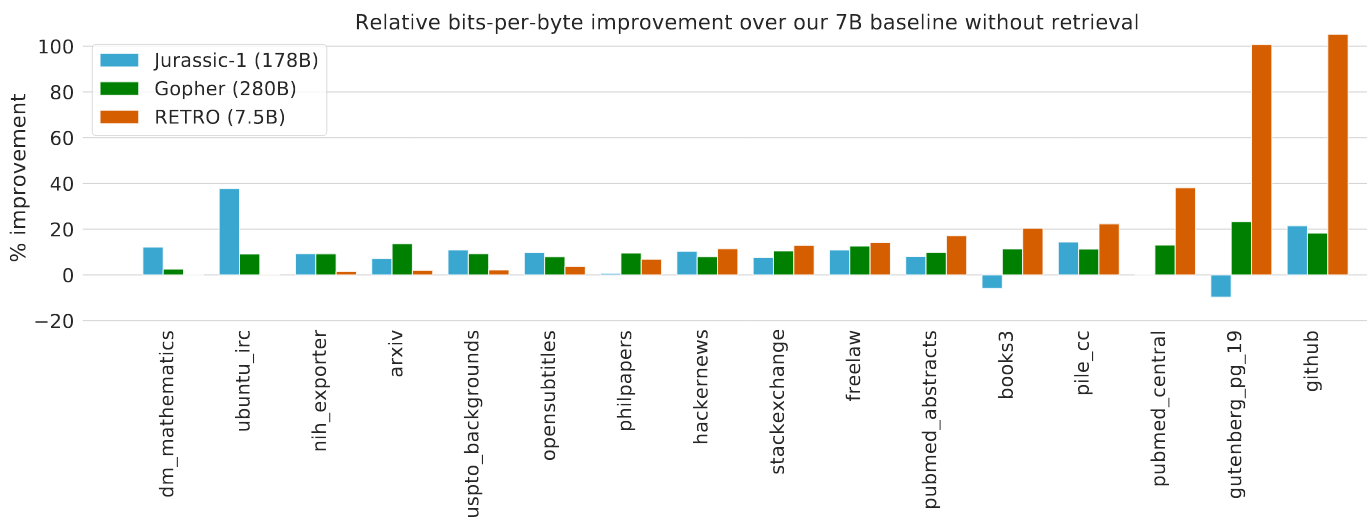
Among some tasks, Retro can outperform the models whose parameters are much more than the Retro’s.
Perplexity on Wikitext103
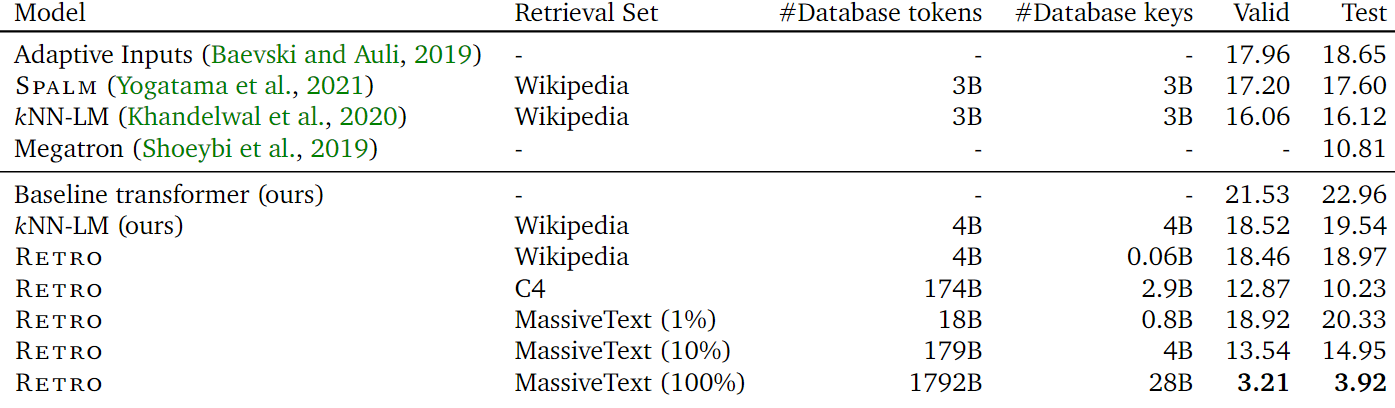
- Retro’s perplexity can be SOTA on the Wikitext103
- Interestingly, the external memory can also have the phenomenon of the underfitting. When using MassiveText(1%), it can underfit the training set. And its performance is worse than the kNN-LM.
Retro Finetuning
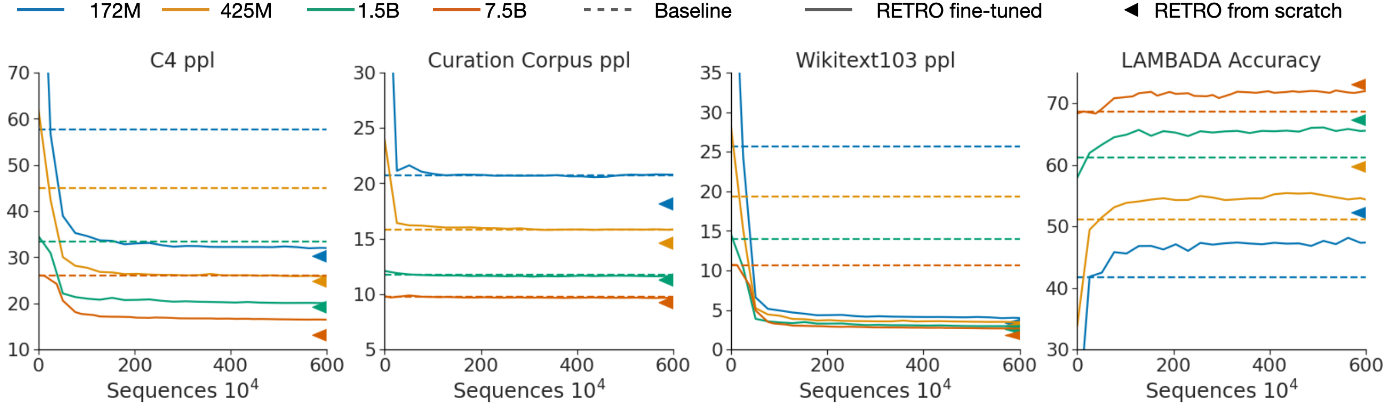
Training from scratch is the most powerful way.
Question Answering Results
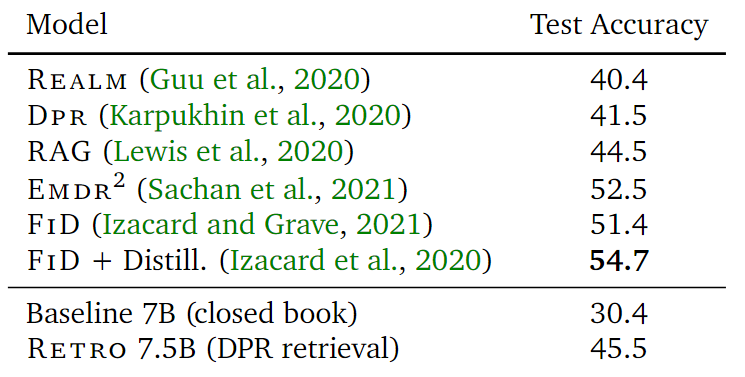
FID + Distill is the SOTA in the Open-Domain Question Answering when the retrieval involves in the training.
Ablation Studies
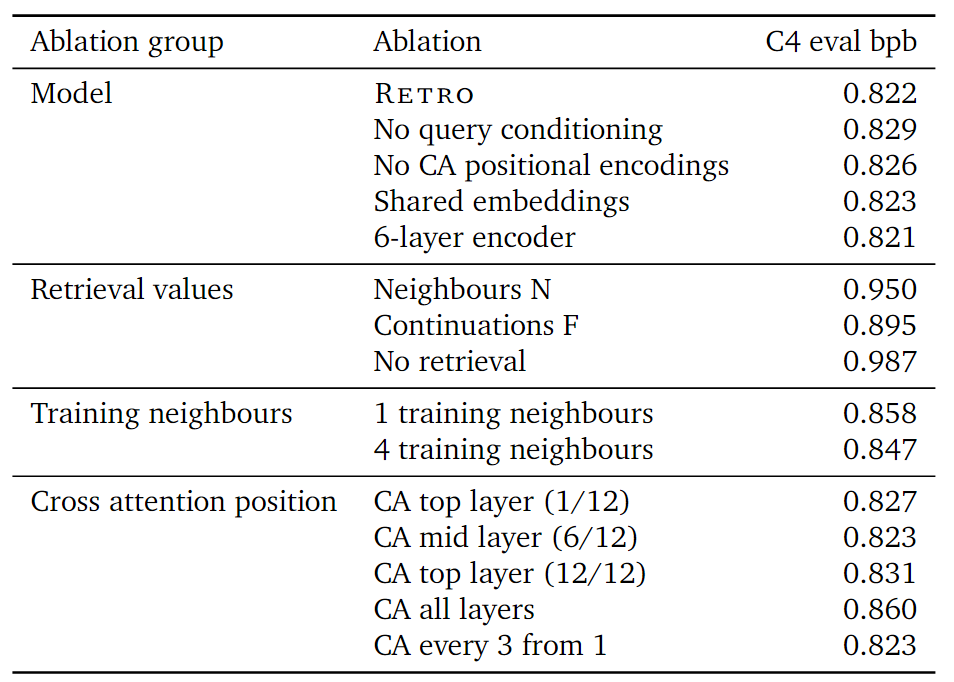
- The continuation of the retrieved chunks do help.
- CA positions are every 3 from 1 or mid layer.
Why work?
To summarize, the Retro incorporates the external neighbours of the input sequence into the Large Language Modelling to scale down the model size while maintaining the performance.
Lessons & Imaginations
- Performance can get improved either by improving the model size or training more data.
- Huge amount of data don’t need too big model to fit in.
- We can scale down the PLM by attending the external information.
- CCA is applied because the external knowledge need to be merged. When applying in MRC, the external information can be:
- the chunked passages
- the broken passages
- the past similar to question-passage pairs
- the knowledge among the input
- the evidence
- The BM25, Edit Distance and LDA can also perform not bad in the retieval.