引子
代理,对于很多人来说并不陌生,尤其是在科研领域,例如在谷歌学术上查找论文的 BibTeX 时。然而,我们常常对网络代理的原理、功能以及如何更好地配置等问题缺乏深入了解。这其实是不可取的,因为网络代理已经深入到我们生活的方方面面,因此,我们更应该去理解它,并让它更好地为我们服务。
然而,网上关于代理具体原理的解释却相对匮乏,大多是零星片段,甚至存在互相矛盾之处。官方文档也往往仅限于对某些具体配置的说明。为此,笔者投入了大量精力,广泛阅读了各类文献和相关博客,力求去芜存菁,汇聚成本文。对于部分文献未涉及之处,笔者结合自身理解进行了补充,但囿于水平,恐有疏漏。若读者能及时指出,笔者将不胜感激!
请注意,本文只讨论计算机网络中的各种原理,若读者将此用于违法之事,读者应个人承担相应责任,与本文和作者无关!
客户端
在展开对具体技术细节的讨论之前,我们先来聊聊「客户端」的选择,因为客户端的些许不同,会导致支持的功能也会存在差异。这里我主要介绍我正在用的几款开源软件,读者可以根据需要进行取舍
本章只会介绍电脑端以及移动端,至于其他的如路由器等,请读者自行查阅资料
电脑端
我个人是在使用 Windows 11 23H2,不过读者不必担心自己是 MacOS 抑或是 Linux,我用的软件是多端适配~
我早期用的软件是 Clash for Windows(CFW),后面 CFW 因为一些不可抗力原因呢就停止了维护,我就去寻找了其他的软件,用过 Clash Verge 一段时间,后面这个也停止维护了,然后目前是有人接力了 Verge 继续开发,叫 Clash Verge Rev,目前我也一直在用,软件也在积极更新中~
UI 还不错,而且最关键的是内置了 Clash Meta(Mihomo)内核,对于小白来说,可以这样理解:内核实现了诸多复杂的功能,比如自定义一些域名的代理,比如浏览 google.com 用香港的节点,目前 Mihomo 也是社区中维护最为频繁而且功能也好用的内核 附上社区中支持 Mihomo 的软件清单供读者参考,本文只会介绍我用过的软件
有些读者可能在用,或者考虑用 Mihomo Party,我个人使用过一段时间,并不推荐,尤其是对于自己写覆写配置的人来说,因为它这个软件很多地方压根不遵循你的配置,比如关于 geodata 的地址,更新频率,甚至你明明在配置里写明 DNS 支持 IPv6,然而你点开正在运行的配置,IPv6 还是 false,有很多地方你都得手动去 check,不建议使用,而上面的 clash verge rev 基本都遵循你的覆写配置,我目前检查下来只有总的 IPv6 控制需要额外去软件设置
移动端
我个人用的是 Android 手机,安卓端一开始我用的是 Clash Meta for Android,也是支持 Mihomo 内核的。然而发现这款软件用途有些局限,手机流量连接时开代理没法访问我的纯 IPv6 服务器,即使配置和软件覆写中 IPv6 全开的情况(解决方案可以看本文的开代理访问IPv6),寻找解决方案时发现另一款软件叫 FlClash, 不仅能够解决我这个问题,UI 支持 material you 以及配置中的图标,就很好看;同时可定义的配置更多
说完了 Android,我还有一台 iPad,目前是在用 sing-box和 Shadowsocket,后者自不必多说,比较简单的代理软件,前者也在用的原因是其免费,同时也支持比较复杂的功能,比如 AdGuard DNS Filter,当然读者如果已经购买了 Surge 等软件,可以继续沿用~
当你访问时
接下来讨论一些更有趣的,本章会详细介绍客户端向你的代理软件发起请求时,Mihomo 内核的 DNS 工作流程,比如浏览器访问某个网页
如果一开始客户端访问的就是 IP,就不用费很多事,直接到关于 IP 的规则,比如是直连还是走代理等,不需要域名解析。下面是一个简单的 IP 规则举例,CIDR 表示 IP 的范围
rules:
# 以 192.168.1.0 开始的 IP 段
- IP-CIDR,192.168.1.0/23,DIRECT # 走直连
- IP-CIDR,103.151.150.0/23,香港-代理 # 走香港-代理
走代理的意思是说,代理软件将访问的请求发送给你的代理节点(这里就是香港的服务器),然后代理节点将访问接收到的 IP 或者域名,最后代理节点会把响应返回给代理软件;走直连的意思是直接和该 IP 进行连接
而对于域名的访问就要复杂一些,故而接下来将详细讨论客户端向某个域名发起请求会具体发生什么,为了让概念更加清晰易懂,下面的流程图中省略了 IP 规则的部分 部分参考自 Mihomo 官方文档
flowchart TB Start[客户端发起请求] --> fake[fake-ip 反查] fake[fake-ip 反查] --> Domain[基于域名匹配规则] fake --> |fakeip-filter|system[系统解析 DNS] Domain --> |匹配过程中|IP[遇到 IP 规则] Domain --> reject[匹配到 Reject 规则] Domain --> |匹配到直连规则|Cache IP --> Cache Domain --> |匹配到代理规则|Remote[通过代理服务器解析域名并建立连接] Cache --> |Cache 未命中|NS[匹配 nameserver-policy 并查询 ] Cache --> |Cache 命中|Get NS --> |匹配成功| Get[将查询到的 IP 用于匹配 IP 规则] NS --> |没匹配到| NF[nameserver/fallback 并发查询] NF --> Get[查询得到 IP] Get --> |缓存 DNS 结果|Cache[(查询 DNS 缓存)]
确定域名前
在讲具体的域名规则之前,我们还得确保一件事:就是你的代理软件得知道你访问的「目标域名」,听起来是不是有点意外。有时候代理软件不知道你访问的目标域名是什么,比如以下情况:
假设你的浏览器没有直接通过代理协议(如 socks5 或 http 代理)将请求发送到代理软件,而是依赖系统的普通网络栈。在这种情况下,浏览器会向系统发起域名解析,操作系统会通过本地的 DNS 服务器将域名解析为 IP 地址。然后,浏览器使用这个 IP 地址建立连接。这种场景下,浏览器完全没有直接传递域名给代理,代理只知道「一个 IP 地址」
那这个时候很有可能就会有问题,因为代理压根不知道你访问的是哪个域名:故而需要引入一个新的机制:fake-ip 因为 redir-host 已经过时了,故本文并不会进行讨论
fake-ip 的定义出自 RFC3089,关于 fake-ip 的介绍,Clash 知识库介绍的很好,我这里摘抄一下:
fake-ip 池的默认 CIDR 是 198.18.0.1/16,一个保留的 IPv4 地址空间(CIDR 表示的是一个 IP 范围)
当 DNS 请求被发送到 Clash DNS 时,Clash 内核会通过管理内部的域名和其 fake-ip 地址的映射,从池中分配一个空闲的 fake-ip 地址
以使用浏览器访问 https://google.com 为例
- 浏览器向 Clash DNS 请求 google.com 的 IP 地址
- Clash 检查内部映射并返回 198.18.1.5
- 浏览器向 198.18.1.5 的 80/tcp 端口发送 HTTP 请求
- 当收到 198.18.1.5 的入站数据包时,Clash 查询内部映射,发现客户端实际上是在向 google.com 发送数据包
- a. Clash 可能仅将域名发送到 SOCKS5 或 shadowsocks 等出站代理,并与代理服务器建立连接;b. 或者 Clash 可能会基于 SCRIPT、GEOIP、IP-CIDR 规则或者使用 DIRECT 直连出口查询 google.com 的真实 IP 地址
我总结一下:简而言之,fake-ip 通过拦截客户端的解析请求从而知道真正需要访问的域名是什么,进而可以使用提前设置的分流规则
当然,你可能会疑惑,我明明都输入了 google.com 了,为什么还要「多此一举」呢?尽管大多数时候客户端的请求中都指明了访问的域名,但有些时候并不能直接获得域名,所以得都拦截下来,以确保代理知道你要访问的域名
刚刚我们也说过会有系统接管 DNS 解析的情况,有些我们并不需要通过代理软件进行解析,比如访问 localhost:8080 这种本地的情况,抑或是压根不需要代理的 Windows 软件等,这个时候利用 fakeip-filter 来做到:
dns:
# 配置不使用 fake-ip 的域名,代理跳过解析,让系统自己解析
fake-ip-filter:
- "*" # 只匹配 localhost 等没有. 的主机名
- "*.lan"
- "xbox.*.microsoft.com"
- "+.xboxlive.com"
- "localhost.ptlogin2.qq.com"
确定域名后
代理软件通过 fake-ip 确认了客户端想要访问的域名之后,就要开始匹配域名的相关规则,以下是一个域名规则示例:
rules:
- DOMAIN-SUFFIX,baidu.com,REJECT # 直接拒绝
- DOMAIN-SUFFIX,google.com,美国-代理 # 走代理
- DOMAIN-SUFFIX,baidu.com,DIRECT # 直连
示例说的是以下情况:
- 当你访问的域名以 baidu.com 结尾时,直接拒绝该请求
- 当你访问的域名以 google.com 结尾时,走美国代理,此时就由你的美国服务器来负责解析域名对应的 DNS,访问后把响应返回给你
- 或者是以 baidu.com 结尾,走直连
域名直连
走代理和拒绝没啥多说的,继续讲直连的过程,会进一步查询 DNS 缓存,当发现需要访问的域名在缓存内存在时,就直接获得了其 IP
当 cache 命中不了的时候,接着会到 nameserver-policy 来解析,nameserver 中文是「域名服务器」,具体负责将域名转成 IP,policy 代表着某种解析的策略,我们可以设置一些规则让某些域名让 A 域名服务器来解析,而另一些让 B 来解析。设置正确的好处是可以更准确更快地获得 IP,比如你访问国内,用阿里和腾讯的域名服务器来解析;访问国外的,就用谷歌和 Cloudflare 的来解析
再具体介绍 nameserver-policy 之前,先得判断域名是否是国内或国外,这里需要借助 geosite 和 geoip 的帮助,并成为 geodata。这两个资源文件将一些域名和 IP 对应的地区进行配对,当然,有些情况里面还会有自定义的分组,比如所有 Steam 相关的域名和 IP 等
我们可以配置 geodata 的加载地址,我这里用的是 Mihomo 社区中的配置,有些读者 可能在用 Loyalsoldier 的 v2ray-rules-dat 和 geoip,其实 Mihomo 社区的跟前面两个基本上是一致的,比较大的不同是社区的删掉了 geosite 中大部分的广告域名,因为仅靠 geosite 来屏蔽广告是很有限的。我本人是用了其他的来规避广告(下文会具体展开),所以就选择社区的版本。这里还用 cdn 了进行加速,原生的 GitHub release 有时候可能访问不上
# 用 dat 格式文件来加载 geoip,默认为 false,用 mmdb 格式文件
geodata-mode: true
geo-auto-update: true # 自动更新 geodata
geo-update-interval: 24 # 24 小时更新一次
# 自定义 geodata 的加载地址
geox-url:
# geoip,geosite 存储的是 IP 和域名对应的分组,可能是国家,也可能是某些分组,比如广告
geoip: "https://cdn.jsdelivr.net/gh/MetaCubeX/meta-rules-dat@release/geoip.dat"
geosite: "https://cdn.jsdelivr.net/gh/MetaCubeX/meta-rules-dat@release/geosite.dat"
# 这里用 dat 就没必要配置 mmdb
# ASN 指的是一些注册的企业,机构和个人,参见 https://github.com/VirgilClyne/GetSomeFries/wiki/%F0%9F%8C%90-ASN#%E7%AE%80%E4%BB%8B
asn: "https://cdn.jsdelivr.net/gh/MetaCubeX/meta-rules-dat@release/GeoLite2-ASN.mmdb"
接着我们来设置 nameserver-policy,国内的全送给阿里和腾讯的域名服务器进行解析,而国外的由谷歌和 Cloudflare 来负责解析
dns:
nameserver-policy:
# private 其实指的是 Reserved IP(保留地址),比如 192.168.0.0
"geosite:cn,private":
- https://dns.alidns.com/dns-query # 阿里
- https://doh.pub/dns-query # 腾讯
"geosite:geolocation-!cn": # 已经包含了 gfw 类
- "https://dns.cloudflare.com/dns-query"
- "https://dns.google/dns-query"
如果设置了 nameserver-policy 并且匹配成功,就会通过指定的 nameserver 来进行解析,如果解析成功,就直接获得 IP;而如果解析失败,也就失败了,并没有兜底规则!
解析失败并没有兜底规则这一点提醒我们用起来需要注意风险,网上有一些配置预先设置了很多的策略,比如阿里的服务,腾讯的服务,B 站的服务等等全部进行分开解析,放到策略里。我个人并不推荐,因为有时候解析会错误,我之前是模仿网上的配置将 B 站的解析送到腾讯的域名服务器,然后就遇到过解析不出来的情况。反正多一次并发 DNS 查询并不会很大程度影响性能,何必要大费周章地预置呢,还会增加风险 :doge
当没有设置 nameserver-policy 时,就走全局的 nameserver 来解析。读到这里读者可能会疑惑,上述的 nameserver-policy 不是已经涵盖了所有的网站嘛,国内和国外,这里的 nameserver 设置是否不必要了呢?答案是肯定有必要,因为 geosite 是一个规则集,有些网站并未包含在这些规则内,比如常见的个人小型博客,所以还需要默认的 nameserver 的规则
dns:
nameserver:
# 不要用 IP
- https://dns.alidns.com/dns-query # 阿里
- https://doh.pub/dns-query # 腾讯
fallback:
- "https://dns.cloudflare.com/dns-query"
- "https://dns.google/dns-query"
# 如果满足了 filter 的条件,就用 nameserver 的解析结果
# 否则就用 fallback 的解析结果
fallback-filter:
geoip-code: CN
这里一旦设置了 fallback 项,nameserver 并发解析的同时,还会向 fallback 里的域名服务器并发请求,然后根据设置的 fallback-filter 来决定最终用谁的解析结果。这里是说如果是国内就用阿里和腾讯的解析结果,而国外就用谷歌和 Cloudflare 的解析结果,避免 DNS 被污染
多余的 DNS 解析
有些时候当你的配置文件写的不对时,代理软件会进行多余的 DNS 解析,比如说当你访问 google.com,明明你的规则集里写了遇到谷歌走代理,但你打开代理软件 log 时发现谷歌域名对应的 IP 还是被解析好了,这就是上图中画的另外一种情况:你的 IP 规则写到了域名规则中,比如这种情况:
rules:
- IP-CIDR,103.151.150.0/23,香港-代理
- DOMAIN-SUFFIX,google.com,美国-代理
Mihomo 内核是从上往下的顺序进行检查的,也就是说当代理软件发现有 IP 相关的规则,它会首先将 google.com 转换成 IP,然后判断是否满足,将 IP 规则混在域名规则中造成了多余的 DNS 解析,因为对于 google.com 的访问我们本来就是直接送给代理节点来进行访问,所以在写配置时要注意域名和 IP 规则进行分开,通常域名规则在上面,而 IP 规则在下
写好配置
在本章我们将写一个 Mihomo 内核的覆写(override)文件,无论以后用何种机场,都可以用覆写文件自动转换,而不必依靠于机场自带的各种落后的分流规则,形同虚设的节点分组等
注意:这里是 Mihomo 内核的覆写文件,若是 sing-box 等,请进行修改转换
语法
Mihomo 内核的覆写文件有两种方式,一种是 yaml,另一种是 JavaScript,这里介绍更为简单的 yaml 形式,yaml 语法主要就如下几种:
# 字典:a = {'b': 1}
a:
b: 1
# 数组:a = [b, c]
a:
- b
- c
稍微复杂一点的是「锚点」的应用,这里直接摘自 Mihomo 官方对 yaml 语法的介绍
& 锚点和 * 别名,可以用来引用,& 用来建立锚点,« 表示合并到当前数据,* 用来引用锚点
如下示例中,因 p 这个键在 mihomo 内置中不存在,所以在 mihomo 解析配置会被忽视
如合并时有重复的项,则不会去合并
锚点的使用示例
p: &p
type: http
interval: 3600
health-check:
enable: true
url: https://www.gstatic.com/generate_204
interval: 300
proxy-providers:
provider1:
<<: *p
url: ""
path: ./proxy_providers/provider1.yaml
provider2:
<<: *p
type: file
path: ./proxy_providers/provider2.yaml
等同于
不用锚点的内容
proxy-providers:
provider1:
type: http
interval: 3600
health-check:
enable: true
url: https://www.gstatic.com/generate_204
interval: 300
url: ""
path: ./proxy_providers/provider1.yaml
provider2:
interval: 3600
health-check:
enable: true
url: https://www.gstatic.com/generate_204
interval: 300
type: file
path: ./proxy_providers/provider2.yaml
节点组和策略组
接着我们对节点来进行分组,下面用了正则的写法,HK 节点的意思是说,当发现以香港,或 HK,或 Hong 以及 🇭🇰 开头,并且[网站, 地址, 剩余, ..., 节点]等词没有出现过,一旦出现,就放弃匹配,关于正则表达式,不确定的读者可以去该网站进行查看
FilterHK: &FilterHK "^(?=.*(香港|HK|Hong|🇭🇰))^(?!.*(网站|地址|剩余|过期|时间|有效|网址|禁止|邮箱|发布|客服|订阅|节点)).*$"
FilterJP: &FilterJP "^(?=.*(日本|JP|Japan|🇯🇵))^(?!.*(网站|地址|剩余|过期|时间|有效|网址|禁止|邮箱|发布|客服|订阅|节点)).*$"
对节点按照地区分好组之后,这里建立选择节点的方式:自动测速和手动选择
自动选择和手动选择
# 策略组参数锚点
# 手动选择参数
Select:
&Select {
type: select,
url: "https://cp.cloudflare.com",
disable-udp: false,
hidden: false,
include-all: true,
}
# 自动测速参数
Auto:
&Auto {
type: url-test,
url: "https://cp.cloudflare.com",
interval: 300,
tolerance: 50,
disable-udp: false,
hidden: true,
include-all: true,
}
然后就有我们的节点策略组了,filter 的意思是针对所有的代理节点留下满足条件的
proxy-groups:
# 自动选择,会自动测速,选择最快的
- { name: 🇭🇰 - 自动选择, <<: *Auto, filter: *FilterHK }
# 手动选择
- { name: 🇭🇰 - 手动选择, <<: *Select, filter: *FilterHK }
其他地区相关的节点组和策略组按照如上方式编写即可,编写好之后我们就开始进行按照不同的访问目的来选择不同地区的节点,下面是编了三组,一组是节点选择,包含了自动,手动和 DIRECT;第二组是自动选择,包含所有的自动选择,以及 telegram 的节点策略组,而且默认是用香港的节点(第一个出现的即为默认)
proxy-groups 示例
proxy-groups:
- name: 节点选择
type: select
proxies: [自动选择, 手动选择, DIRECT]
url: https://cp.cloudflare.com
icon: https://raw.githubusercontent.com/Orz-3/mini/master/Color/Static.png
- name: 自动选择
type: select
proxies: [🇭🇰 - 自动选择, 🇯🇵 - 自动选择, 🇰🇷 - 自动选择, 🇸🇬 - 自动选择, 🇺🇸 - 自动选择, 🇬🇧 - 自动选择, 🇫🇷 - 自动选择, 🇩🇪 - 自动选择, 🇹🇼 - 自动选择, 🇲🇾 - 自动选择, 🇹🇭 - 自动选择, 🇻🇳 - 自动选择, 🇹🇷 - 自动选择, 🇦🇷 - 自动选择]
url: https://cp.cloudflare.com
icon: https://raw.githubusercontent.com/Orz-3/mini/master/Color/Urltest.png
- name: Telegram
type: select
proxies: [🇭🇰 - 自动选择, 🇯🇵 - 自动选择, 🇰🇷 - 自动选择, 🇸🇬 - 自动选择, 🇺🇸 - 自动选择, 🇬🇧 - 自动选择, 🇫🇷 - 自动选择, 🇩🇪 - 自动选择, 🇹🇼 - 自动选择, 🇲🇾 - 自动选择, 🇹🇭 - 自动选择, 🇻🇳 - 自动选择, 🇹🇷 - 自动选择, 🇦🇷 - 自动选择]
icon: https://raw.githubusercontent.com/Orz-3/mini/master/Color/Telegram.png
分流规则
讲完了基础语法,终于来到了最激动的分流规则部分了,本节的大部分规则来自于 Sukka Surge,感谢 Sukka 的贡献~
首先我们得加载识别访问域名或者 IP 是否是广告的一些规则集,然后我们才能去选择策略,比如 REJECT
规则集很多配置有重复的地方,这里就先建立锚点,然后来引用锚点使得配置文件更整洁
规则参数
# 规则参数 [每12小时更新一次订阅规则,更新规则时使用(节点选择)策略]
RuleSet_classical:
&RuleSet_classical {
type: http,
behavior: classical,
interval: 43200,
format: text,
proxy: 节点选择,
}
RuleSet_domain:
&RuleSet_domain {
type: http,
behavior: domain,
interval: 43200,
format: text,
proxy: 节点选择,
}
RuleSet_ipcidr:
&RuleSet_ipcidr {
type: http,
behavior: ipcidr,
interval: 43200,
format: text,
proxy: 节点选择,
}
然后就可以编写规则集,这里不一一列出琐碎的细节,用广告的例子来具体讲一下怎么写,读者应能举一反三
广告规则集
rule-providers:
reject_non_ip_no_drop:
<<: *RuleSet_classical
url: https://ruleset.skk.moe/Clash/non_ip/reject-no-drop.txt
path: ./rule_set/sukkaw_ruleset/reject_non_ip_no_drop.txt
reject_non_ip_drop:
<<: *RuleSet_classical
url: https://ruleset.skk.moe/Clash/non_ip/reject-drop.txt
path: ./rule_set/sukkaw_ruleset/reject_non_ip_drop.txt
reject_non_ip:
<<: *RuleSet_classical
url: https://ruleset.skk.moe/Clash/non_ip/reject.txt
path: ./rule_set/sukkaw_ruleset/reject_non_ip.txt
reject_domainset:
<<: *RuleSet_domain
url: https://ruleset.skk.moe/Clash/domainset/reject.txt
path: ./rule_set/sukkaw_ruleset/reject_domainset.txt
reject_extra_domainset:
<<: *RuleSet_domain
url: https://ruleset.skk.moe/Clash/domainset/reject_extra.txt
path: ./sukkaw_ruleset/reject_domainset_extra.txt
reject_ip:
<<: *RuleSet_classical
url: https://ruleset.skk.moe/Clash/ip/reject.txt
path: ./rule_set/sukkaw_ruleset/reject_ip.txt
上面的几个规则集一共有两个方面,域名和 IP 来拦截广告,我们配置分流规则务必按照域名和 IP 规则分开,而且是 IP 规则在下,从而避免不必要的 DNS 解析。下面的规则中有一个是 REJECT-DROP,跟直接 REJECT 不同的是该策略收到请求后,直接静默直到超时为止,适合那些被拒绝就立马再发起请求的情况
分流规则示例
# 分流规则
rules:
# 非 IP 类规则必须与 IP 类规则分开,避免不必要的 DNS 解析
# 先是拒绝类,优先级最高,引自 Sukka,包含 uBlock Origin、AdGuard、EasyList 等
- RULE-SET,reject_non_ip,REJECT
- RULE-SET,reject_domainset,REJECT
- RULE-SET,reject_extra_domainset,REJECT # 可能开启后对性能有影响
- RULE-SET,reject_non_ip_drop,REJECT-DROP
- RULE-SET,reject_non_ip_no_drop,REJECT
... # 这里是另外其他的域名规则
# IP 类规则
- RULE-SET,reject_ip,REJECT
# 兜底规则
- MATCH,节点选择
这样就写好了一个分流规则,同时分流规则的最后应该是兜底规则,MATCH 的意思是无论什么都会去匹配
再补充一下常见的几种域名规则,方便读者自定义:
rules:
- DOMAIN,ad.com,REJECT # 完整的域名
- DOMAIN-SUFFIX,google.com,auto # 域名以 google.com 结尾
- DOMAIN-KEYWORD,google,auto # 域名包含关键词 google
- DOMAIN-REGEX,^abc.*com,PROXY # 利用正则来匹配,以 abc 开头,包含 com
接着讲讲另一种规则集的常用写法,就是从上文说到的 geodata 来进行配置,也就是从 geosite 和 geoip 来匹配某种特殊用途,前者是域名,后者是 IP。这里屏蔽了 Windows 的一些脏东西,geosite 合并了 crazy-max 的规则
rules:
# 引自 crazy-max 的规则,WIN-SPY 和 WIN-EXTRA 是 Windows 的附加的隐私跟踪域名
# WIN-UPDATE 是 Windows 的自动更新域名
- GEOSITE,WIN-SPY,REJECT
- GEOSITE,WIN-EXTRA,REJECT
- GEOSITE,WIN-UPDATE,REJECT
但同时也要注意,当你相关规则多了之后,可能会有误杀的情况,比如如上的三条规则就导致你登不上 outlook,所以可以通过代理软件的 log 查看有哪些是必须的,然后救回来即可,不要盲目抄规则
rule:
# 引自 crazy-max 的规则,WIN-SPY 和 WIN-EXTRA 是 Windows 的附加的隐私跟踪域名
# WIN-UPDATE 是 Windows 的自动更新域名
# 有些域名可能被误杀,可以通过 log 来进行补救
- DOMAIN-REGEX,outlook.office.*.com,DIRECT
- DOMAIN-SUFFIX,login.microsoftonline.com,DIRECT
- GEOSITE,WIN-SPY,REJECT
- GEOSITE,WIN-EXTRA,REJECT
- GEOSITE,WIN-UPDATE,REJECT
那么如果你想从 geosite 中找到自己想要的类,比如 telegram 呢?可以本地下载 geosite.dat,然后直接记事本打开,然后去搜你想要找的类别,必须要大写搜索,小写会搜到很多域名部分,geosite 中类是大写的,比如 TELEGRAM。另外,有些类是比较杂,会以 “CATEGORY-” 开头,可以搜搜看是否有想要的
至此你应该能够自己写配置了,接着讲一下我的配置中关于 Sukka 规则的取舍
- 广告部分,我全部拿过来,并且启用
- CDN 部分,我是专门定制了新的 CDN 节点策略组,专门用自建的节点或者低倍率节点,因为 CDN 通常流量较大
- 对于苹果和微软可以直连的,直接 DIRECT;不能的则分别建立苹果和微软策略组
- 对于流媒体部分,我并没有做过多区分,因为我也不咋用,所以就直接放到节点选择了
- 关于 AIGC的,我专门建立了策略组,默认是美国的节点,港澳台用不了
- global 的就直接走节点选择,domestic 就走 DIRECT
另外一点就是移动端如何运用覆写配置呢?我是将电脑端正在运行的配置保存为文件,然后手机导入文件即可
巧用配置
终于来到了配置的应用环节, 这里分享一些日常可以用到的配置,方便读者使用
内网开梯子打不开
很多读者发现开着梯子访问公司内网或者校园网打不开,当你读完了上文就会明白,因为当你开了系统代理之后,代理软件接管了 DNS 解析的过程,也就是说代理软件会向常用的域名服务器去查找你的公司或者校园网的域名,这当然是找不到的,内网的域名在公网肯定是解析不到的。那么就可以用到我们之前说的 nameserver-policy 来做到,当我们匹配到特定域名,就让内网的域名服务器来解析,而不是用公网的
那么如何找到内网的 nameserver 呢?找到 WiFi,然后点开属性,找到以下的即可:
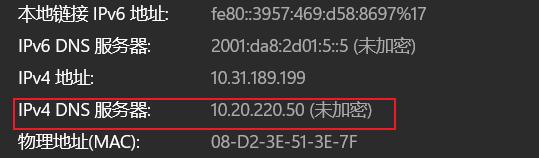
然后配置好就可以开着系统代理正常访问内网了,下面说的是任何以 xxx.edu.cn 结尾的都可以走我们预设的 DNS 服务器
dns:
nameserver-policy:
"+.xxx.edu.cn": 10.20.220.50
解锁流媒体
不少机场不同的节点对不同流媒体的解锁情况不一样,那么就可以将可以解锁的代理节点放在一个策略组内,然后将所有的流媒体的分流规则都导到这个策略组即可~
想要直连 tracker
有些读者可能像我一样日常生活中会用到一些 public 或是 private 的 tracker,有些服务器可能是国外,但是 tracker 一般都能直连,我们不想要代理去连接 tracker,就可以利用分流规则
幸好先前引入的 geosite 中有一部分是融合了TrackersList以及blackmatrix7 / ios_rule_script,包含了public 和 private 的 tracker
rules:
- GEOSITE,CATEGORY-PUBLIC-TRACKER,DIRECT # 公共 tracker
- GEOSITE,CATEGORY-PT,DIRECT # 私有 tracker
使用学校学术资源
有些时候开着代理软件会不可避免的用代理节点来访问学术网站,导致没办法用到学校购买的资源,下载不了论文等,此时我们就可以针对学术网站来制定一个策略组,节点配置就只有一个直连,这样就可以使得即使代理开着,也能用到学校资源
下列域名规则取自于 hexiao,另外注意,该域名规则应该加在 global 之前,因为优先级是从上而下的,如果一开始匹配到 global,就直接结束了
rules:
# Academic
- DOMAIN,tuchong.com,DIRECT
- DOMAIN-SUFFIX,taylorandfrancis.com,DIRECT
- DOMAIN,dl.acm.org,DIRECT
- DOMAIN,acm-prod.disqus.com,DIRECT
- DOMAIN-SUFFIX,sciencedirectassets.com,DIRECT
- DOMAIN-SUFFIX,readspeaker.com,DIRECT
- DOMAIN-SUFFIX,webofknowledge.com,DIRECT
- DOMAIN-KEYWORD,pubmed,DIRECT
- DOMAIN-KEYWORD,springer,DIRECT
- DOMAIN-KEYWORD,ieee,DIRECT
- DOMAIN-KEYWORD,elsevier,DIRECT
- DOMAIN-KEYWORD,sciencedirect,DIRECT
- DOMAIN-KEYWORD,nature,DIRECT
- DOMAIN-KEYWORD,tandfonline,DIRECT
- DOMAIN-SUFFIX,elsevier.com,DIRECT
- DOMAIN-SUFFIX,edu.cn,DIRECT
- DOMAIN-SUFFIX,webofscience.com,DIRECT
- DOMAIN-SUFFIX,tandfonline.com,DIRECT
- DOMAIN-SUFFIX,link.springer.com,DIRECT
- DOMAIN-SUFFIX,onlinelibrary.wiley.com,DIRECT
- DOMAIN-SUFFIX,sciencedirect.com,DIRECT
- DOMAIN-SUFFIX,taylorfrancis.com,DIRECT
开代理访问 IPv6
无论是电脑还是手机端,如果开了代理的情况下还想要访问纯 IPv6 的站点,需要开启 IPv6 相关的设置,一般来说会有总的 IPv6 开关以及 DNS 中的 IPv6 开关。这里有个误区就是你以为你的覆写文件中已经写过开启 IPv6 就可以了,实际上软件层面还要同时去打开设置
- 电脑端的 Clash-verge-rev:设置 -> Clash 设置 -> IPv6
- 手机端的 FlClash:工具 -> 覆写 -> DNS -> 开启覆写 DNS 以及 IPv6;以及工具 -> 覆写 -> 基础 -> IPv6 开关
需要注意的是,当你用 FlClash 开启了 DNS 覆写,那么软件中的设置项就接管了覆写配置中提前设置好的信息,就需要你手动将覆写配置中的信息输入到软件里
注意,有些情况如果域名服务器设置不正确,也会影响开代理加载 IPv6。尽量以域名而非 IP 来设置域名服务器!
致谢
尽管上文均已提及本文所参考的来源,但有必要再一次列出以示感谢,排名不分先后~