区分真实样本
前面的两种是为了去估计配分函数,接下来要介绍的 InfoNCE 虽然带个 NCE,但这个的目的不是要预估配分函数,他是直接像上篇应用 NCE 的方法一样,直接采用自归一化,即:
$$ p(\boldsymbol{w}|\boldsymbol{c}) = \frac{u_{\boldsymbol{\theta}}(\boldsymbol{w}, \boldsymbol{c})}{1} $$
首先对于每个训练样本来说,我们再从噪声分布$q(x)$中采样$k-1$个样本,我们的目的即是区分出真实样本:
$$ \begin{align} L(\boldsymbol{\theta}) & = -\mathbb{E}_{\boldsymbol{w}, \boldsymbol{c} \sim \mathcal{D}; \boldsymbol{w}_{j} \sim q} \log \frac{p(\boldsymbol{w}|\boldsymbol{c})}{p(\boldsymbol{w}|\boldsymbol{c})+\sum_{j=1}^{k-1}q(\boldsymbol{w}_{j})}\\ & = -\mathbb{E}_{\boldsymbol{w}, \boldsymbol{c} \sim \mathcal{D};\boldsymbol{w}_{j} \sim q} \log \frac{u_{\boldsymbol{\theta}}(\boldsymbol{w}, \boldsymbol{c})}{u_{\boldsymbol{\theta}}(\boldsymbol{w}, \boldsymbol{c}) + \sum_{j=1}^{k-1} q(\boldsymbol{w}_{j})} \end{align} $$
最小化上述 loss 到底有什么好处呢?
互信息来访
对于训练样本$i$来说,它是真实样本的概率为:
$$ \begin{align} p(d=i) & = \frac{p(\boldsymbol{w}_{i}|\boldsymbol{c})\prod_{j=1, i\neq j}^{k}q(\boldsymbol{w}_{j})}{\sum_{j=1}^{k}p(\boldsymbol{w}_{j}|\boldsymbol{c})\prod_{l=1,l\neq j}^{k}q(\boldsymbol{w}_{l})} \\ &= \frac{\frac{p(\boldsymbol{w}_{i}|\boldsymbol{c})}{q(\boldsymbol{w}_{i})}}{\sum_{j=1}^{k} \frac{p(\boldsymbol{w}_{j}|\boldsymbol{c})}{q(\boldsymbol{w}_{j})}} \end{align} $$
转换的方法即是上下同除以$\prod_{i=1}^{k} q(\boldsymbol{w}_{i})$
InfoNCE 的目的即为正确区分出真实样本,而真实样本都来自训练集(与噪声集区分),也就是说对于 loss 而言,最优解即为$u_{\boldsymbol{\theta}}(\boldsymbol{w}, \boldsymbol{c})$正比于 density ratio:
$$ u_{\boldsymbol{\theta}}(\boldsymbol{w}_{i}, \boldsymbol{c}) \propto \frac{p(\boldsymbol{w}_{i}|\boldsymbol{c})}{q(\boldsymbol{w}_{i})} $$
我们知道,互信息的计算如下:
$$ I(\boldsymbol{w}, \boldsymbol{c}) = \text{KL}(p(\boldsymbol{w}, \boldsymbol{c})\|p(\boldsymbol{w})p(\boldsymbol{c})) = \mathbb{E}_{\boldsymbol{w}, \boldsymbol{c} \sim \mathcal{D}} \log \frac{p(\boldsymbol{w}, \boldsymbol{c})}{p(\boldsymbol{w})p(\boldsymbol{c})} $$
为了和上述 loss 有关,很自然做出以下变化:
$$ I(\boldsymbol{w}, \boldsymbol{c}) = \mathbb{E}_{\boldsymbol{w}, \boldsymbol{c} \sim \mathcal{D}} \log \frac{p(\boldsymbol{w}|\boldsymbol{c})p(\boldsymbol{c})}{p(\boldsymbol{w})p(\boldsymbol{c})} = \mathbb{E}_{\boldsymbol{w}, \boldsymbol{c} \sim \mathcal{D}} \log {\color{#337dff}\frac{p(\boldsymbol{w}|\boldsymbol{c})}{p(\boldsymbol{w})}} $$
也就是说如果我们要$u_{\boldsymbol{\theta}}(\boldsymbol{w}, \boldsymbol{c})$来表示互信息,还得$q(x) = p(x)$,也就是噪声分布即为模型分布(unconditioned)
那么:
$$ u_{\boldsymbol{\theta}}(\boldsymbol{w}_{i}, \boldsymbol{c}) \propto \frac{p(\boldsymbol{w}_{i}|\boldsymbol{c})}{{\color{#337dff}p(\boldsymbol{w}_{i})}} $$
此时完整的 loss 即为:
$$ L(\boldsymbol{\theta }) = -\mathbb{E}_{\boldsymbol{w}, \boldsymbol{c} \sim \mathcal{D}; \boldsymbol{w}_{j} \sim q} \log \frac{u_{\boldsymbol{\theta}}(\boldsymbol{w}, \boldsymbol{c})}{\sum_{j=1}^{k} u_{\boldsymbol{\theta}}(\boldsymbol{w}_{j}, \boldsymbol{c})} $$
当我们要使得训练样本$\boldsymbol{w}$是真实样本的概率变得最大,即一定程度最大化$u_{\boldsymbol{\theta}}(\boldsymbol{w}, \boldsymbol{c})$,然后最小化$u_{\boldsymbol{\theta}}(\boldsymbol{w}_{j}, \boldsymbol{c})$,即最大化$\boldsymbol{w}, \boldsymbol{c}$之间的互信息,最小化负样本与$\boldsymbol{c}$之间的互信息
注意:现在用的时候并非像一开始通过真实样本的概念,而是可以将$\boldsymbol{w}, \boldsymbol{c}$看成是一对正样本,噪声样本看作负样本
Hardness-Aware
同时 InfoNCE 会着重关照那些跟真实样本$\boldsymbol{c}$更相似的负样本,这类也叫做「Hard-Negative」,而相应地会轻视一些与$\boldsymbol{c}$本来就没有那么相似的负样本,即「Hardness-Aware」
$$ \begin{align} L(\boldsymbol{\theta }) & = - \mathbb{E}_{\boldsymbol{w}, \boldsymbol{c} \sim \mathcal{D};\boldsymbol{w}_{j}\sim q} \log \frac{u_{\boldsymbol{\theta }}(\boldsymbol{w}, \boldsymbol{c})}{u_{\boldsymbol{\theta }}(\boldsymbol{w}, \boldsymbol{c})+\sum_{j=1}^{k-1} u_{\boldsymbol{\theta }}(\boldsymbol{w}_{j}, \boldsymbol{c})} \\ &= -\mathbb{E}_{\boldsymbol{w}, \boldsymbol{c} \sim \mathcal{D};\boldsymbol{w}_{j}\sim q} \log \frac{\exp(s_{\boldsymbol{w}, \boldsymbol{c}} )}{\exp(s_{\boldsymbol{w}, \boldsymbol{c}})+\sum_{j=1}^{k-1}\exp(s_{\boldsymbol{w}_{j}, \boldsymbol{c}})} \\ &= -\mathbb{E}_{\boldsymbol{w}, \boldsymbol{c} \sim \mathcal{D};\boldsymbol{w}_{j} \sim q} \left[s_{\boldsymbol{w}, \boldsymbol{c}} - \log\left( \exp(s_{\boldsymbol{w}, \boldsymbol{c}})+\sum_{j=1}^{k-1}\exp(s_{\boldsymbol{w}_{j},\boldsymbol{c}}) \right)\right] \end{align} $$
对于$\boldsymbol{w}_{j}$而言,与$\boldsymbol{c}$的相似性越大,则在损失函数中占比越大,可以看成是惩罚越大,然而仅凭这个没办法做到上述性质,比如下面的 loss 也可以:
$$ L_{\text{simple}}(\boldsymbol{\theta }) = \mathbb{E}_{\boldsymbol{w}, \boldsymbol{c} \sim \mathcal{D}; \boldsymbol{w}_{j} \sim q} \left[-s_{\boldsymbol{w}, \boldsymbol{c}} + \sum_{j=1}^{k-1} s_{\boldsymbol{w}_{j}, \boldsymbol{c}}\right] $$
然而实验证明,这个 loss 效果并不是很好
接着,我们来求下损失函数相对于$s_{\boldsymbol{w}_{j}, \boldsymbol{c}}$的偏导:
不妨就对单个样本$\boldsymbol{w}, \boldsymbol{c}$来看:
$$ \frac{ \partial L_{\text{simple}} }{ \partial s_{\boldsymbol{w}_{j}, \boldsymbol{c}} } = 1 $$
也就是说 loss 对于所有$s_{\boldsymbol{w}_{j}, \boldsymbol{c}}$的变化一样敏感,即「一视同仁」,没有给损失函数的优化注入其他信息
$$ \frac{ \partial L }{ \partial s_{\boldsymbol{w}_{j},\boldsymbol{c}} } = \frac{\exp(s_{\boldsymbol{w}_{j}, \boldsymbol{c}})}{\exp(s_{\boldsymbol{w},\boldsymbol{c}} )+ \sum_{j=1}^{k-1}\exp(s_{\boldsymbol{w}_{j}, c})} $$
而对于 InfoNCE 而言,对于所有负样本而言,分母是固定的,而「分子越大」,即$s_{\boldsymbol{w}_{j}, \boldsymbol{c}}$越大,则此时 loss 对于$s_{\boldsymbol{w}_{j}, \boldsymbol{c}}$的变化则越敏感
总结说就是,InfoNCE 这种 loss 在优化时会注入一种偏好,更偏向于把与真实样本相似的噪声样本给区分开来
温度系数
一般现在用的时候,还会加入一个调节因子:$\tau$
$$ L(\boldsymbol{\theta})= -\mathbb{E}_{\boldsymbol{w}, \boldsymbol{c} \sim \mathcal{D}; \boldsymbol{w}_{j} \sim q} \log \frac{\exp(s_{\boldsymbol{w}, \boldsymbol{c}}/\tau )}{\exp(s_{\boldsymbol{w}, \boldsymbol{c}}/\tau)+\sum_{j=1}^{k-1}\exp(s_{\boldsymbol{w}_{j}, \boldsymbol{c}}/\tau)} $$
那么:
$$ \frac{ \partial L }{ \partial s_{\boldsymbol{w}_{j},\boldsymbol{c}} } = \frac{1}{\tau}\frac{\exp(s_{\boldsymbol{w}_{j}, \boldsymbol{c}}/\tau)}{\exp(s_{\boldsymbol{w},\boldsymbol{c}}/\tau )+ \sum_{j=1}^{k-1}\exp(s_{\boldsymbol{w}_{j}, c}/\tau)} $$
推论 1:当$\tau$很小时,比如$0.02$那么由上式可得 loss 会格外关注于将与真实样本相似的噪声样本给区分开。换句话说,$\tau$越小,对 hard-negative 的惩罚越大
下面我们引入一个 kernel 来衡量一个分布的均匀性(uniform),$f(\boldsymbol{x})$代表模型输出的表示
$$ L_{\text{uniformity}}(f;t) = \log \mathbb{E}_{\boldsymbol{x}, \boldsymbol{y} \sim \mathcal{D}} \left[e^{-t\|f(\boldsymbol{x}) - f(\boldsymbol{y})\|_{2}^{2}}\right](t \in \mathbb{R}_{+}) $$
作者采用不同的$\tau$来对比模型产生表示的均匀性
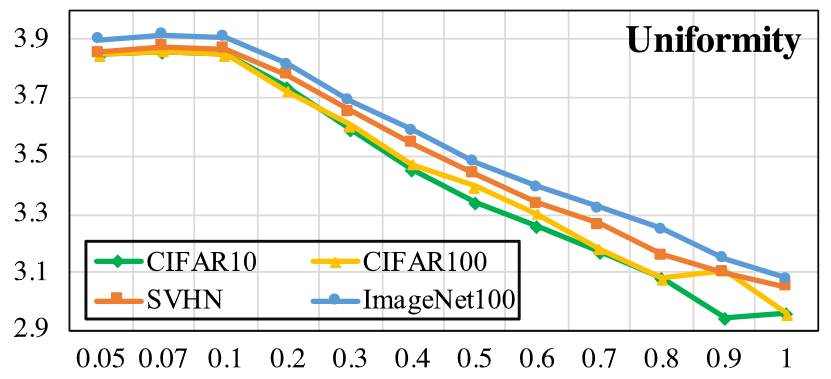
当$\tau$比较小时,模型产生的表征空间更加均匀,随着$\tau$的增大,均匀性被破坏
而对于一个好的对比学习的表征空间应该满足「locally clustered,globally uniform」,当表征均匀分布在球面上时,此时用一个超平面(线性分类器)便可分开,比如下图

推论 2:当$\tau$较小时,用 infoNCE loss 训出的模型表征空间比较均匀,当$\tau$增大时,表征空间的均匀性被逐步破坏
上代码
当下的算力已经足够支撑直接用概率而非自归一化了,其实会发现 InfoNCE loss 跟多分类交叉熵损失一样:
import torch.nn.functional as F
def infoNCE(q_vectors, c_vectors, labels, tau=1):
"""Compute the InfoNCE Loss in
http://arxiv.org/abs/1807.03748.
Params:
- q_vectors: Tensor. Shape: (bs, d_model). Vector presentation of query.
- c_vectors: Tensor. Shape: (num_pos_neg_contexts, d_model). Vector presentation of context.
- labels: Tensor. Shape: (bs, ). Indices for the positive contexts.
- tau: Scalar. The parameter to control penalty on hard negatives (smaller => harder).
A good initialization value can be 0.02 or 0.05.
Examples:
>>> q_vectors = torch.randn((2, 4))
>>> c_vectors = torch.randn((4, 4)) # each query has 4 contexts
>>> labels = torch.tensor([1, 3])
>>> print(infoNCE(q_vectors, c_vectors, labels))
"""
scores = (q_vectors @ c_vectors.T) / tau
return F.cross_entropy(scores, labels)