如何高效训练或推理大模型一般在两点:如何装得下以及如何更快
这里讲一些主要的并行概念,不会深挖原理,只会介绍 key points,看它们分别为加速和适配显存做了什么贡献
Data Parallelism
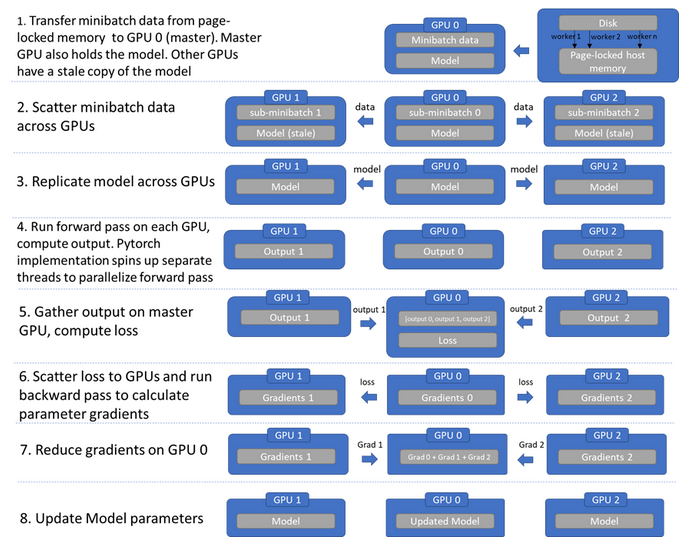
对于常规的单机多卡用户而言,数据并行(DP)应该不陌生,在 PyTorch 中就有 DistributedDataParallel,主要原理就是将模型复制到每个 GPU 上,并将数据进行切分,然后在每个 GPU 上单独进行前向传播,接着在主进程上将输出聚集,将输出进行分发,在主进程上聚集梯度,然后进行更新,再将更新好的模型复制到其他 GPU 上
当我们说 DP Degree 为 2 时,则需要两张 GPU
得益于并行计算,相比于单卡速度会有不错的提升,需要注意的是,速度的增长很难是线性的,因为中间各种分发和聚集的过程会有通信的损失,这一点在高效训练中经常需要考虑
ZeRO Data Parallelism
ZeRO 是DeepSpeed开发的,下面来简要讲讲:
可以看到 Baseline 代表的就是上面原始的 DP,可以看到蓝色的代表模型参数,绿色代表的是优化器状态,剩下的是梯度
$os, g, p$ 分别代表的是优化器状态,梯度以及参数。ZeRO 有三个阶段:$P_{os}, P_{os+g}, P_{os+g+p}$,$P$的意思是切分
- Stage 1:我们只对优化器状态进行切分
- Stage 2:同时对优化器状态和梯度进行切分
- Stage 3:对优化器状态,梯度和参数进行切分
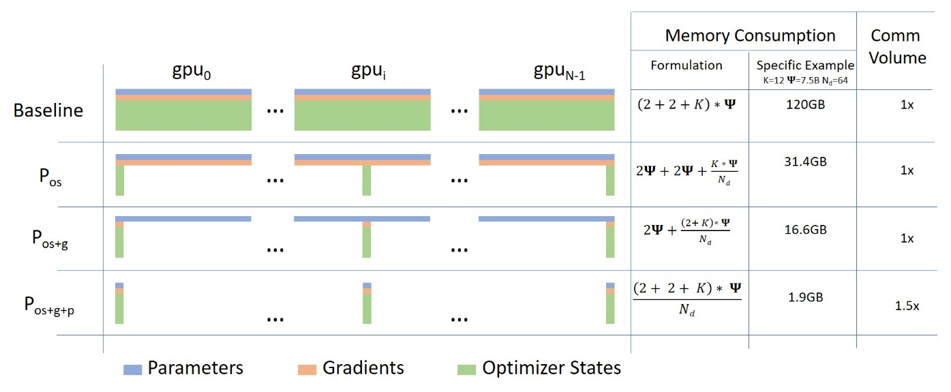
其实不用想的很复杂,跟原始的 DP 相比,你可以理解为只是原来在每张 GPU 上的优化器状态,梯度和参数变成了一部分而已
同时,需要注意,ZeRO 需要在 FP16 进行计算
因而,ZeRO 主要是为训练而生的,只有 Stage 3 和推理相关
Tensor Parallelism
张量并行就是原来一张卡上进行的张量操作在多张 GPU 上进行,可以看到原来的$\mathbf{XA}$可以被拆分为以下过程:
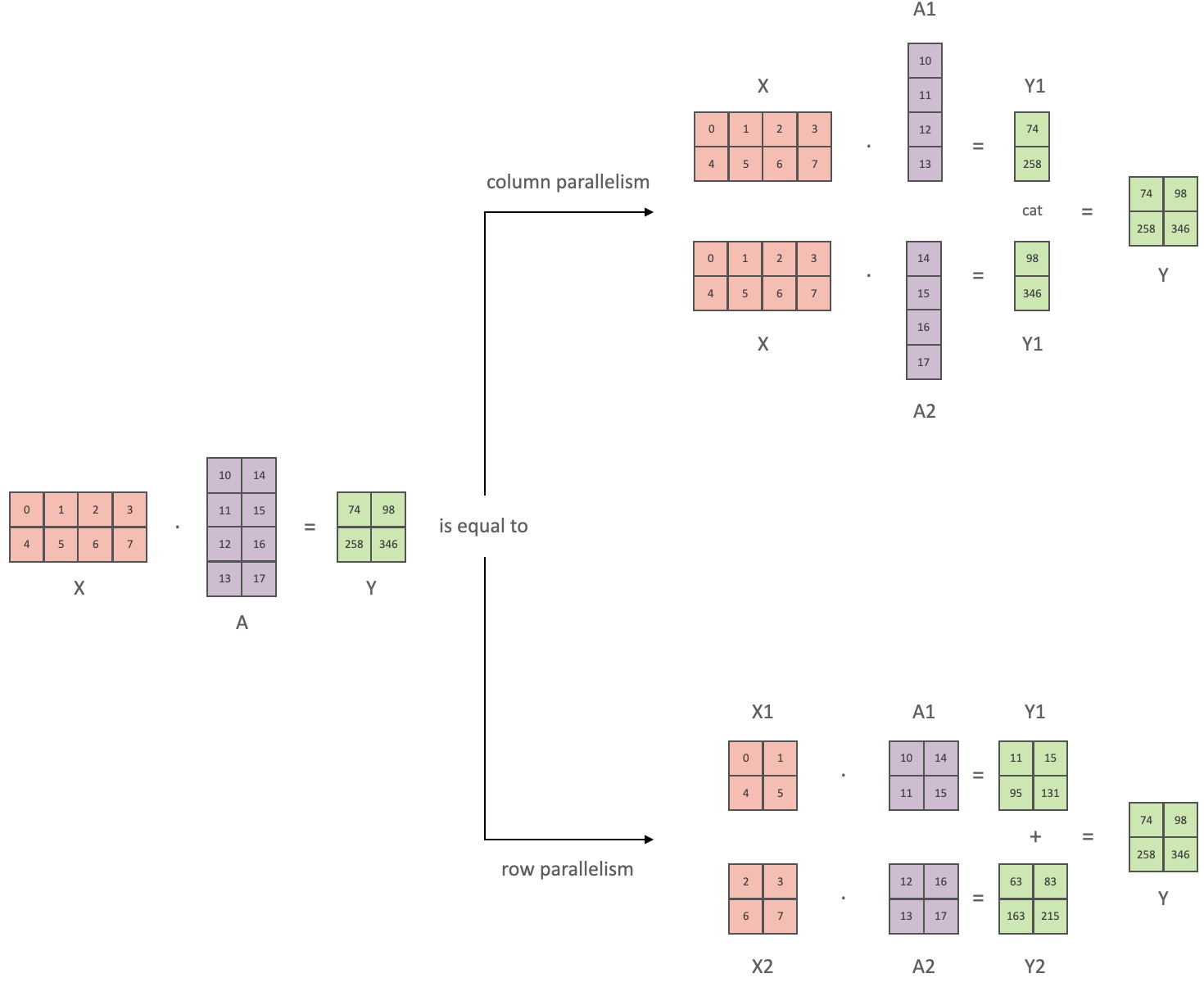
本质上就是将张量按照行或列进行拆分,分别计算,然后聚集得到结果,这样的好处是可以将很大的张量放到几个 GPU 上来适配显存
由于张量计算是比较普遍的,因而若想进行 TP,对于设备间的通信要求比较高,当你有好几个节点的时候,不建议节点之间使用 TP,通信将是负累,在Bloom里作者说PCIe速度比节点间要快得多
Pipeline Parallelism
流水线并行的操作主要就是为了适配显存的,当你的显卡不足以放下模型的时候,你可以将模型的组成部分进行切分然后放到不同的 GPU 上
=================== ===================
| 0 | 1 | 2 | 3 | | 4 | 5 | 6 | 7 |
=================== ===================
GPU0 GPU1
比方说上图,模型一共有 8 层,我们将模型一分为二,放到不同的 GPU 上面,当我们涉及到那一层,就把相关的中间输出和数据转移到哪张卡上
原始的 PP 效率问题很严重,当你在某张卡上进行运算时,其他卡都是空闲状态
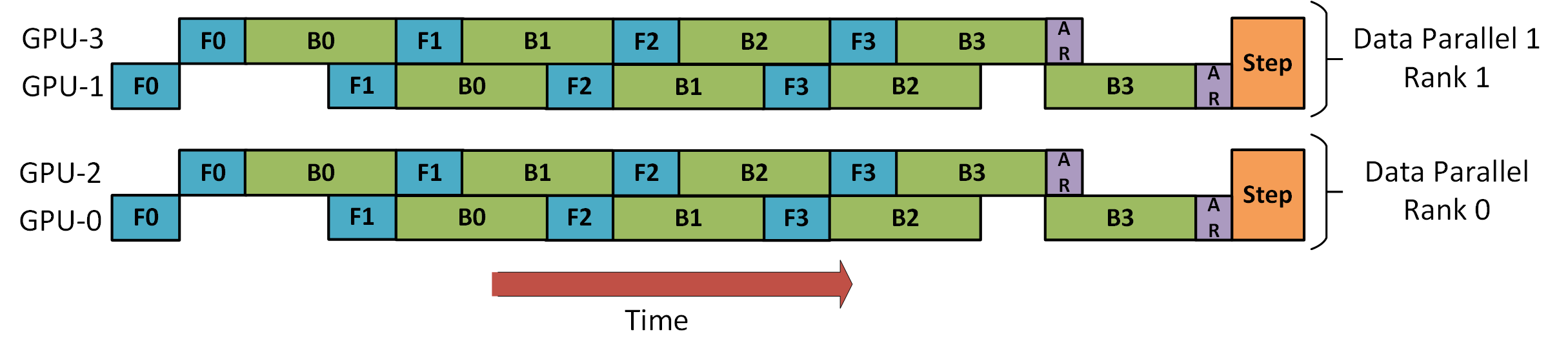
在下图中,上图是原始的 PP,从上往下分别代表四个 GPU,F 是代表 Forward,而 B 代表 Backward
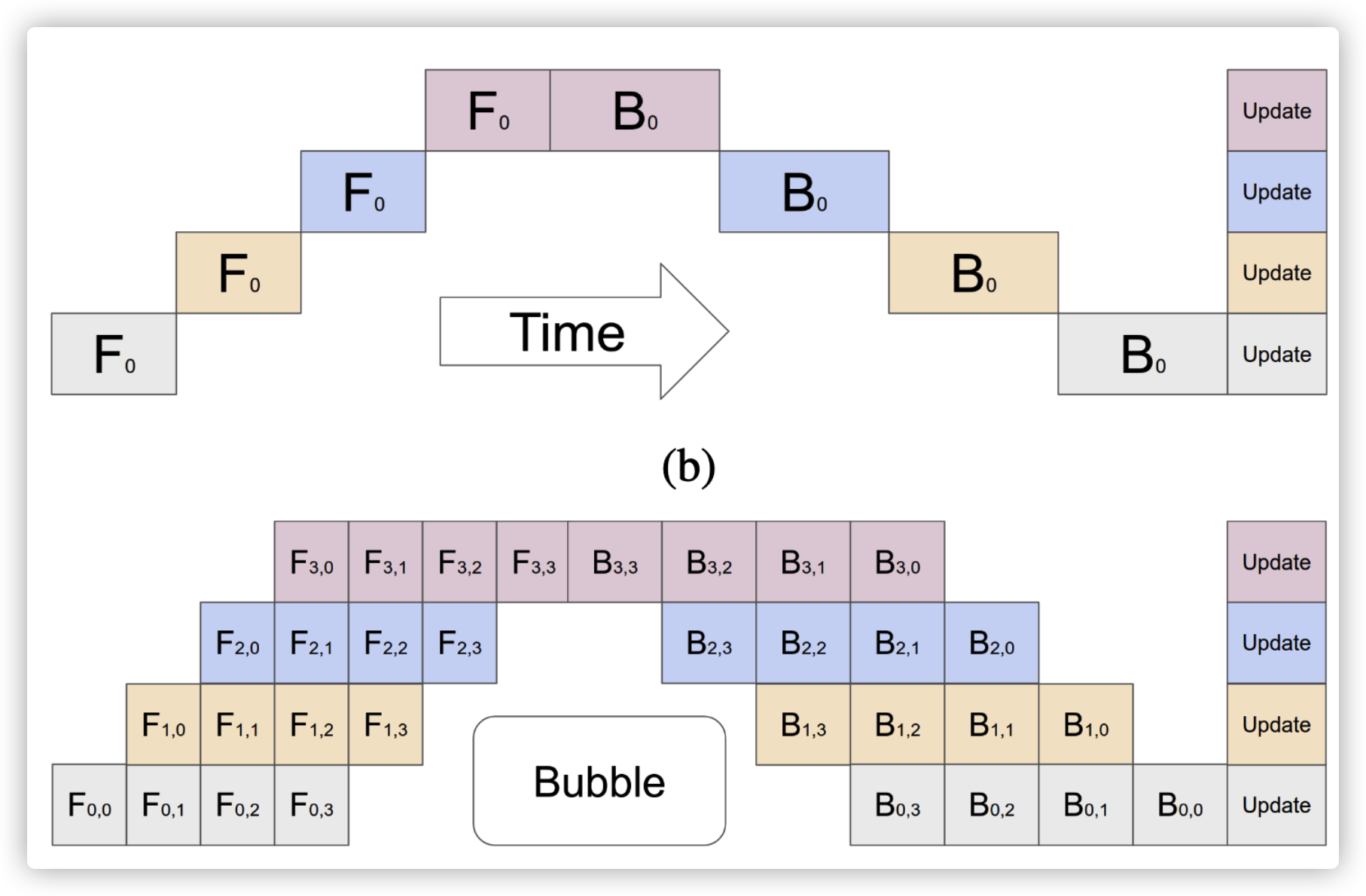
下面的即为改进方案,将每个 Batch 切分为 micro-batches,拿灰色的举例,被切分为 4 个 micro-batches
在 Bloom 作者的实践中,当一个词表很大(250K)时,word embedding 会比 transformer 的 block 占用更大显存,此时就需要将 word embedding 层也看做是一个 transformer block
DP+PP
当然,不同的并行方法也可以组合,DP+PP 就是一个例子。假设我们目前有 4 张卡,我们可以将 2 张卡就看做是一张卡,那我们就可以进行 DP 为 2 的并行,而两张卡里又可以进行 PP 为 2 的并行
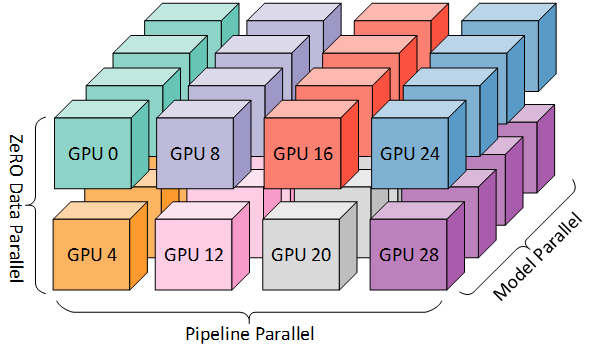
DP+PP+TP
当然,这两者还可以和 TP 结合在一起,DP=PP=TP=2,这时候就需要八张卡了,这种并行方式叫做 3D Parallel
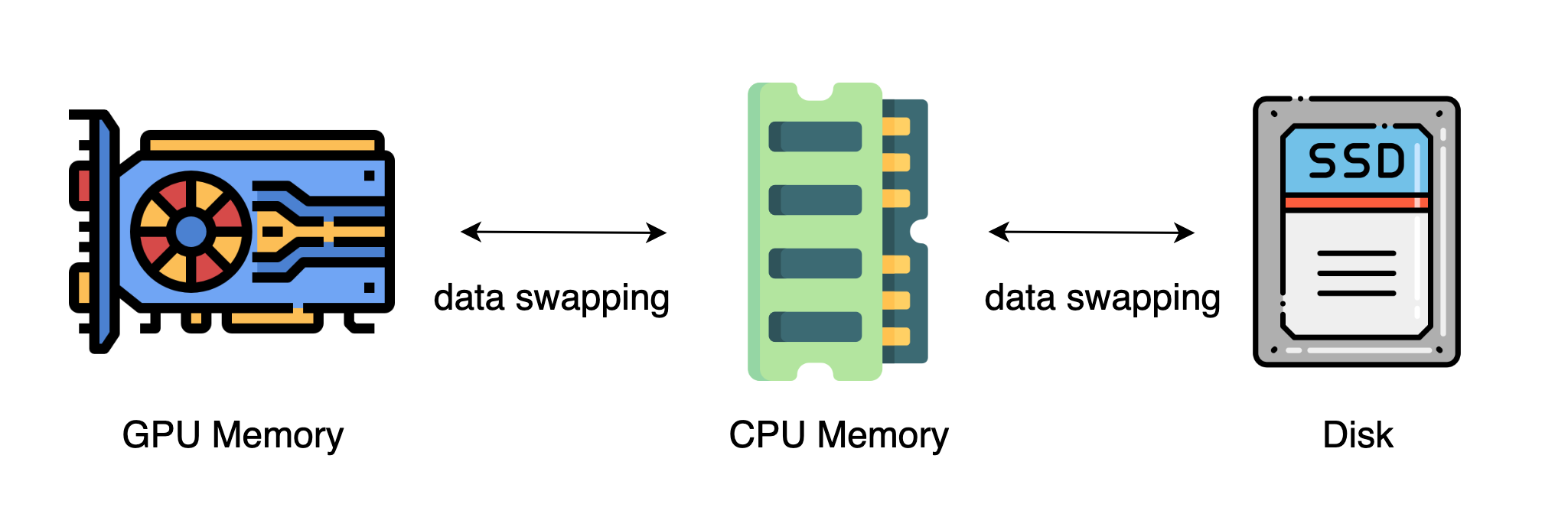
异构空间管理
上面无论是 PP 还是 TP 都在说,放另一张卡上,假设我没有那么多卡咋办,此时就引入了异构操作了,既然放不下,就将模型的 block 进行切分,切分之后尽可能塞满 GPU,放不下的就放在 CPU 和硬盘上
Gemini
Gemini 是 Colossal AI 开发的功能,比 ZeRO 多了动态异构空间管理,同时引入了 chunk 机制,可以让通信比原先更加高效
当用 ZeRO 来切分参数时,每次通信都得申请一块内存,通信完毕再释放,这样就会有内存碎片化的情况;同时,通信是以 Tensor 为粒度进行通信,会导致网络带宽无法充分利用,一般而言,传输消息越长带宽利用率越高
对于以上两个问题,Gemini 采用以下方式解决:
- 将计算顺序连续的一组参数直接存入一个 chunk,避免了内存碎片的问题;
- 如果一个参数多次发生计算,即会发生多次通信,效率不高,就会将和它有关的一组参数全部放进 chunk 里,降低了通信消耗;
- 同时,小 Tensor 无法充分利用带宽,Gemini 会将小 Tensor 聚集起来放在 chunk 里变成大 Tensor,然后一次性计算
ZeRO DP+PP+TP
当 ZeRO DP 和 PP(或是 TP)结合在一起时,一般 Stage 1 是可以激活的,然而 Stage 2 和 3 是否被激活,可以看看激活后是否真正达成了自己的目的,因为激活后通信带来的损失会越来越多
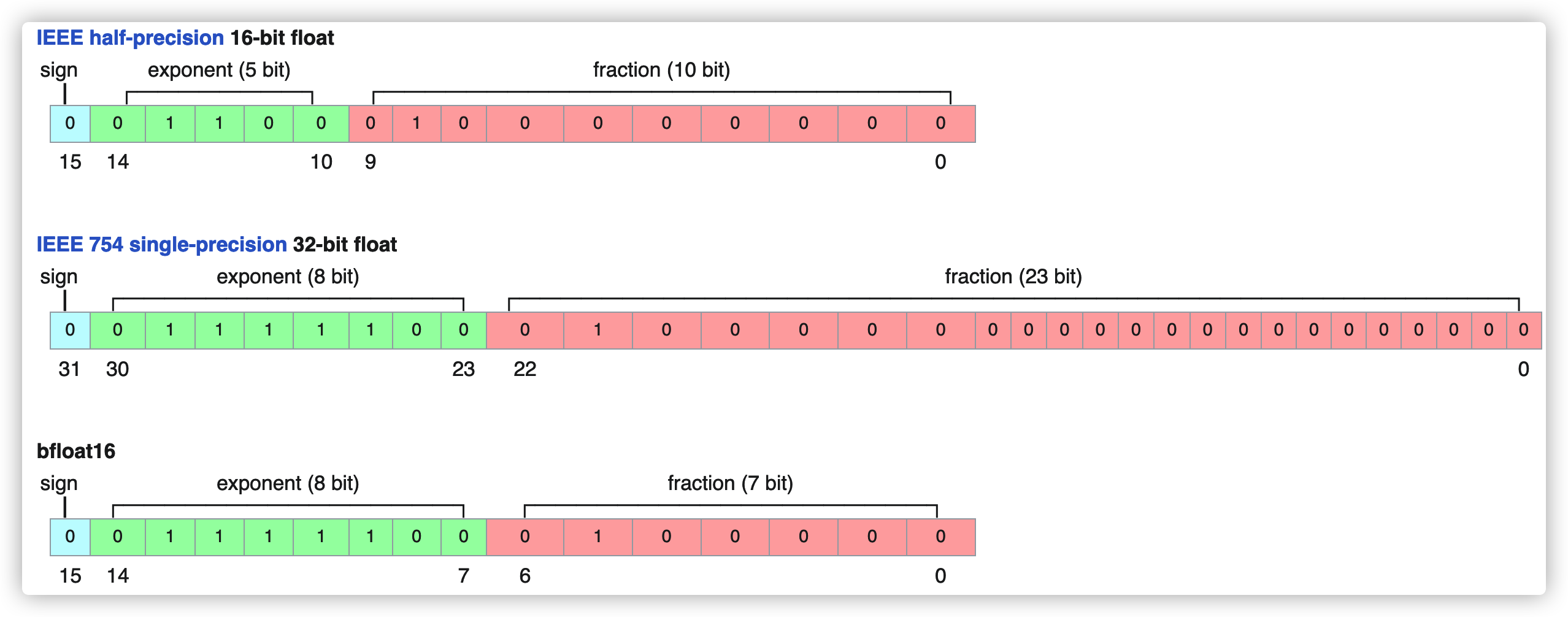
BF16
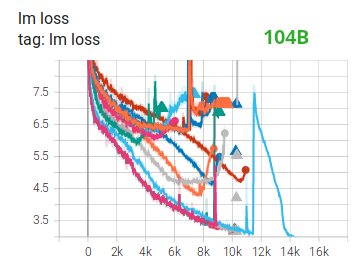
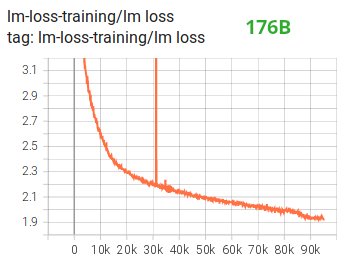
Bloom 的作者不建议训练 LLM 用 FP16,因为在训练过程中很容易遇到数值溢出问题(loss 很不稳定,如下图),而 BF16 不会遭遇这种问题
然而,BF16 带来的代价就是精度会降低,不过只要多训一点,精度就会慢慢上来,所以也可以接受
然而用 BF16 之后 Loss 就平滑不少了
Fused CUDA Kernels
GPUs 一般做两件事:计算以及拷贝数据,当 GPU 拷贝数据时,其计算单元是空闲的,比如以下例子:
c = torch.add(a, b)
e = torch.max([c,d])
原始的做法就是首先从内存读入 a, b 的值,然后进行运算,将 c 的值返回至内存;接下来再从内存读入 c 和 d 的值,进行运算
而融合的 kernel 就不必返回 c 的值到内存,只需要放到 GPU registers,只需要取出 d 的值进行计算即可,比原来更高效。
References
- https://colossalai.org/zh-Hans/docs/features/zero_with_chunk
- https://huggingface.co/blog/bloom-megatron-deepspeed#tensor-parallelism
- https://arxiv.org/abs/1910.02054
- https://www.microsoft.com/en-us/research/blog/deepspeed-extreme-scale-model-training-for-everyone/
- https://en.wikipedia.org/wiki/Bfloat16_floating-point_format#bfloat16_floating-point_format
- https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/