在机器学习中,我们通常会面临一个问题:给定一个集合$\mathbf{S}$,从中寻找$k$个样本构成子集$\mathbf{V}$,尽量使得子集的质量高同时多样性好。比如在推荐系统中,我们就希望给用户推荐的东西尽可能的有质量,同时具有差异性。
而使得采样的子集尽可能具备多样性便是行列式点过程(Determinantal Point Process)大展身手的地方,俗称 DPP
边缘分布
首先引入 DPP 的边缘分布定义,当我们某次采样出子集$\mathbf{A}$,「包括」$\mathbf{V} = [\boldsymbol{v_{1}},\boldsymbol{v_{2}},\dots,\boldsymbol{v_{k}}] \in \mathbb{R}^{{d \times k}}$的概率:
$$ P(\mathbf{V} \subseteq \mathbf{A}) = \det(\mathbf{K_{V}}) $$
$\mathbf{K}$是核矩阵(Kernel Matrix),即:
$$ \mathbf{K}_{ij} = k(\boldsymbol{v_{i}}, \boldsymbol{v_{j}}) $$
$\mathbf{K_{V}}$是由$\mathbf{V}$中元素构成的子矩阵,举个例子,假如$\mathbf{V}=\{ 1,2 \}$,那么:
$$ P(\mathbf{V} \subseteq \mathbf{A}) = \det(\mathbf{K_{V}}) = \left|\begin{array}{cc} \mathbf{K}_{11} & \mathbf{K}_{12} \\ \mathbf{K}_{21} & \mathbf{K}_{22} \end{array}\right| = \mathbf{K}_{11}\mathbf{K}_{22} - \mathbf{K}_{12}^{2} $$
当$\mathbf{K}_{12}$越大,则$\{ 1,2 \}$同时出现在$\mathbf{V}$的概率就越小,从这个角度想,核函数应该是呈现出某种相似性
从正定性出发,严格的定义如下是:$\mathbf{0}\preceq\mathbf{K} \preceq \mathbf{I}$
举个例子:
$$ \mathbf{K} = \begin{bmatrix} 1 & -0.3 \\ -0.3 & 1 \end{bmatrix} $$
其特征值为$0.7, -1.3$,不满足$\mathbf{K}-\mathbf{0} \succeq \mathbf{0}$,即不是半正定矩阵
L-Ensemble
然而,上面边缘定义只是告诉我们采样时,某个子集被「包括」的概率,并非就是这个子集,而这个问题可以通过 L-Ensemble 去解
$$ P(\mathbf{V}=\mathbf{A}) \propto \det(\mathbf{L}) $$
这里的$\mathbf{L}$省略了下标,跟上面的$\mathbf{K}$一样,是跟$\mathbf{V}$元素相关的子矩阵。$\mathbf{L}$矩阵的核函数是内积是$\boldsymbol{v_{i}^{\top}\boldsymbol{v_{j}}}$,$\mathbf{V} = [\boldsymbol{v_{1}},\boldsymbol{v_{2}},\dots,\boldsymbol{v_{k}}] \in \mathbb{R}^{{d \times k}}$
$$ \mathbf{L} = \mathbf{V}^{\top}\mathbf{V} = \begin{bmatrix} \langle \boldsymbol{v_{1}}, \boldsymbol{v_{1}} \rangle & \langle \boldsymbol{v_{1}},\boldsymbol{v_{2}} \rangle & \dots & \langle \boldsymbol{v_{1}}, \boldsymbol{v_{k}} \rangle \\ \langle \boldsymbol{v_{2}},\boldsymbol{v_{1}} \rangle & \langle \boldsymbol{v_{2}},\boldsymbol{v_{2}} \rangle & \dots & \langle \boldsymbol{v_{2}},\boldsymbol{v_{k}} \rangle \\ \vdots & \vdots & \ddots & \vdots \\ \langle \boldsymbol{v_{k}},\boldsymbol{v_{1}} \rangle & \langle \boldsymbol{v_{k}},\boldsymbol{v_{2}} \rangle & \dots & \langle \boldsymbol{v_{k}},\boldsymbol{v_{k}} \rangle \end{bmatrix} $$
注意,这里指的不是概率,而是说概率「正比于」$\mathbf{L}$矩阵的行列式,那么如何计算概率呢?也就是说我们得计算一个归一化常数(normalization constant),可以类比抛硬币,我们得去求总的抛起次数,除以它才能得到概率
引入下述定理:
$$ \sum_{\mathbf{A}\subseteq \mathbf{V} \subseteq \mathbf{S}} \det(\mathbf{L}) = \det(\mathbf{L} + \mathbf{I_{\bar{A}}}) $$
其中$\mathbf{I_{\bar{A}}}$是将单位矩阵中与$\mathbf{A}$相关元素全部置零,举个例子,当$\mathbf{S} = \{ 1,2,3 \}, \mathbf{A}={1,2}$时:
$$ \mathbf{I_{\bar{A}}} = \begin{bmatrix} 0 & 0 & 0 \\ 0 & 0 & 0 \\ 0 & 0 & 1 \end{bmatrix} $$
那么如何求归一化常数呢,即将$\mathbf{A}=\emptyset$,当$\mathbf{A}$为空集时,便包括了所有的情况,即:
$$ P(\mathbf{V}=\mathbf{A}) = \frac{\det(\mathbf{L})}{\det(\mathbf{L}+\mathbf{I})} $$
另外,L-Emsemble 的$\mathbf{K}, \mathbf{L}$对应关系如下:
$$ \begin{align} \mathbf{K} & = \mathbf{L}(\mathbf{L} + \mathbf{I})^{-1} \\ \mathbf{L} & = \mathbf{K}(\mathbf{I}-\mathbf{K})^{-1} \end{align} $$
直观解释
那么,行列式与多样性的直观解释是什么呢?
多样性和相似性的意思正好相反,通常我们会定义相似性为两个向量之间做点积,即为$\boldsymbol{v_{1}}^{\top}\boldsymbol{v_{2}}$,直观上看,两向量夹角的余弦值$\cos \theta$ 越大,相似性越高,反过来看,当$\cos \theta$最小即为两者相似性最差,多样性最好。显然,当两向量正交时多样性最好。
那么,对于一个子集$\mathbf{V} = [\boldsymbol{v_{1}},\boldsymbol{v_{2}},\dots,\boldsymbol{v_{k}}] \in \mathbb{R}^{{d \times k}}$而言,该如何定义它的多样性呢?不难想出,可以通过线性无关向量的数量来定义,若两两都互不线性相关,此时的子集的多样性是最好的。直观上可以转换为构成的超平行体的体积,下方为$k=2,3$时的示意图
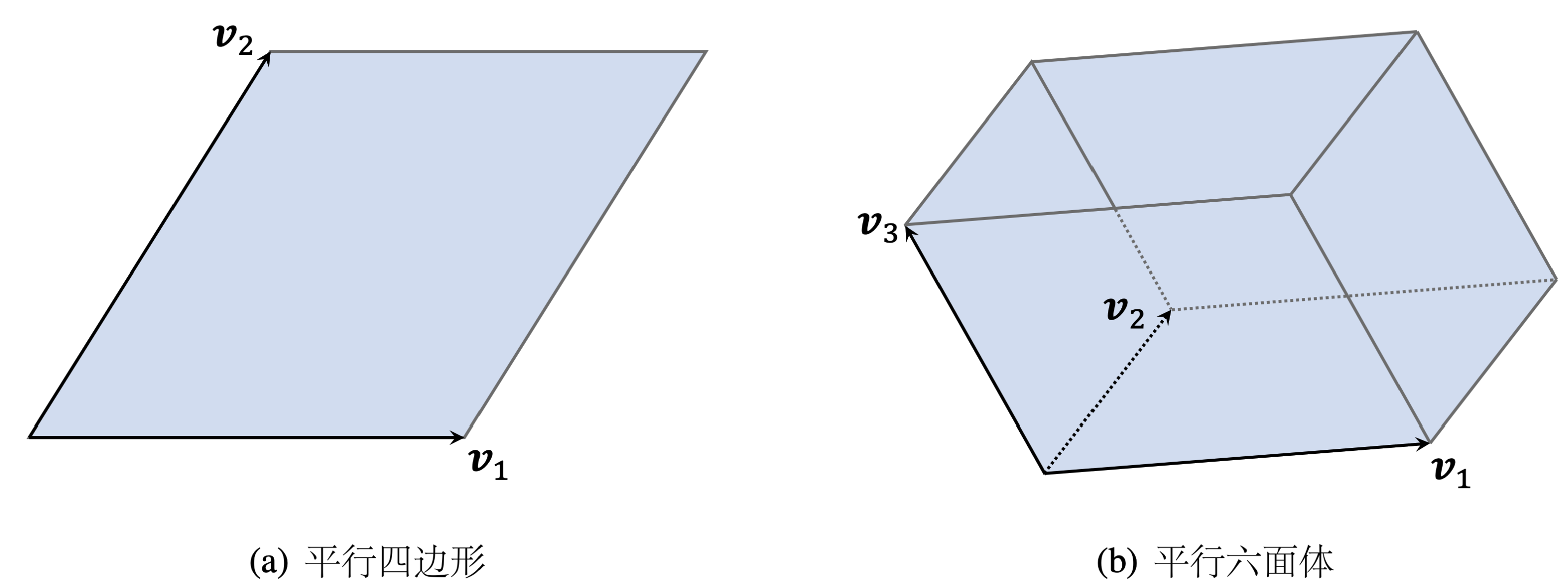
为什么呢?可以拿平行六面体为例,若其中一个向量与其他向量线性相关,那么则会坍缩成一个平面,构不成平行六面体

只有当所有向量两两都线性无关时,构成的超平行体体积最大,即多样性最好
而行列式可以表示体积,下式中$\text{vol}$代表体积(volume),此时$k=d$,$\mathbf{V}$为方阵
$$ \det(\mathbf{V})= \text{vol}(\mathcal{P}(\boldsymbol{v_{1}}, \boldsymbol{v_{2}}, \dots, \boldsymbol{v_{k}})) $$
也就是说,我们可以通过行列式的大小来定义多样性
那么,$\mathbf{L}$的行列式是否也跟体积有关呢?答案是肯定的:
$$ \det(\mathbf{L}) = \text{vol}\bigg(\mathcal{P}(\boldsymbol{v_{1}}, \boldsymbol{v_{2}}, \dots,\boldsymbol{v_{k}})\bigg)^{2} $$
接下来证明这一结论:
由于$k \leq d$,因为$d$维空间至多存在$d$个两两线性无关的向量,那么肯定存在一个$k$维子空间$\mathcal{H}$,存在正交矩阵$\mathbf{R} \in \mathbb{R}^{d \times d}$,对向量$\boldsymbol{v_{1}}, \boldsymbol{v_{2}}, \dots, \boldsymbol{v_{k}}$进行旋转,使得$\mathbf{R}\boldsymbol{v_{1}}, \mathbf{R}\boldsymbol{v_{2}}, \dots, \mathbf{R}\boldsymbol{v_{k}}$都落在子空间$\mathcal{H}$上。不妨设$\mathcal{H}$的基底是前$k$个标准正交基,那么:
$$ \mathbf{R}\boldsymbol{v_{i}} = \begin{bmatrix} \boldsymbol{u_{i}} \\ \mathbf{0} \end{bmatrix} $$
$\boldsymbol{u_{i}} \in \mathbb{R}^{k}$,$\mathbf{0}$一共有$d-k$个,因为用$\mathcal{H}$的基底向量表示,后面只能为$0$,将$\boldsymbol{u_{1}}, \boldsymbol{u_{2}},\dots, \boldsymbol{u_{k}}$当作$\mathbf{U}$的列,就有:
$$ \mathbf{RV} = \begin{bmatrix} \mathbf{U} \\ \mathbf{0} \end{bmatrix}, \mathbf{U} \in \mathbb{R}^{k \times k} $$
显然,$\mathcal{P}(\boldsymbol{u_{1}}, \dots)$与$\mathcal{P}([\boldsymbol{u_{1}};\boldsymbol{0}],\dots )$两者体积相等
$$ \text{vol}(\mathcal{P}(\boldsymbol{u_{1}}, \boldsymbol{u_{2}},\dots, \boldsymbol{u_{k}})) = \text{vol}\bigg(\mathcal{P}\bigg(\begin{bmatrix} \boldsymbol{u_{1}} \\ \boldsymbol{0} \end{bmatrix}, \begin{bmatrix} \boldsymbol{u_{2}} \\ \boldsymbol{0} \\ \end{bmatrix}, \dots, \begin{bmatrix} \boldsymbol{u_{k}} \\ \boldsymbol{0} \end{bmatrix}\bigg)\bigg) $$
那么:
$$ \text{vol}(\mathcal{P}(\boldsymbol{u_{1}}, \boldsymbol{u_{2}}, \dots, \boldsymbol{u_{k}})) = \text{vol}\bigg(\mathcal{P}(\mathbf{R}\boldsymbol{v_{1}}, \mathbf{R}\boldsymbol{v_{2}}, \dots, \mathbf{R}\boldsymbol{v_{k}})\bigg) $$
由于对超平面体进行旋转不改变其体积(注意,这里是旋转而不是一般的线性变换,一般的线性变换不具备该性质)
$$ \text{vol}\bigg(\mathcal{P}(\mathbf{R}\boldsymbol{v_{1}}, \mathbf{R}\boldsymbol{v_{2}}, \dots, \mathbf{R}\boldsymbol{v_{k}})\bigg) = \text{vol}\bigg(\mathcal{P}(\boldsymbol{v_{1}}, \boldsymbol{v_{2}}, \dots, \boldsymbol{v_{k}})\bigg) $$
那么:
$$ \text{vol}(\mathcal{P}(\boldsymbol{u_{1}}, \boldsymbol{u_{2}}, \dots, \boldsymbol{u_{k}})) =\text{vol}\bigg(\mathcal{P}(\mathbf{R}\boldsymbol{v_{1}}, \mathbf{R}\boldsymbol{v_{2}}, \dots, \mathbf{R}\boldsymbol{v_{k}})\bigg) $$
又因为$\mathbf{R}$正交矩阵,即$\mathbf{R}^{\top}\mathbf{R} = \mathbf{I}$,那么:
$$ \mathbf{U}^{\top}\mathbf{U} = (\mathbf{RV})^{\top}\mathbf{RV} = \mathbf{V}^{\top}(\mathbf{R}^{\top}\mathbf{R)}\mathbf{V} = \mathbf{V}^{\top}\mathbf{V} $$
所以:
$$ \det(\mathbf{V}^{\top}\mathbf{V}) = \det(\mathbf{U}^{\top}\mathbf{U}) = \det(\mathbf{U})^{2} = \text{vol}\bigg(\mathcal{P}(\boldsymbol{v_{1}}, \boldsymbol{v_{2}}, \dots, \boldsymbol{v_{k}})\bigg)^{2} $$
从 L-Emsemble 角度看,被采样的概率正比于构成的超平面体的体积,即两两之间线性无关更容易被采样出
Demo
接下来我们用例子来看一下是否 DPP 能够采样出更有多样性的子集
from torch import det, eye
from transformers import set_seed
from transformers import BertModel, BertTokenizer
set_seed(42)
pretrain_path = "fabriceyhc/bert-base-uncased-imdb"
model = BertModel.from_pretrained(pretrain_path).cuda()
tk = BertTokenizer.from_pretrained(pretrain_path)
input_text = [
"I am happy because the weather is extremely good!",
"I hate the bad weather",
"The weather is extremely good!",
]
inputs = tk(input_text, max_length=128, return_tensors="pt", truncation=True, padding=True)
inputs = {k: v.cuda() for k, v in inputs.items()}
outputs = model(**inputs).pooler_output.T
vtv = outputs.T @ outputs
group_12 = vtv[:2][:, [0, 1]]
I = eye(2).cuda()
p_12 = det(group_12) / det(group_12 + I)
group_13 = vtv[[0, 2]][:, [0, 2]]
p_13 = det(group_13) / det(group_13 + I)
print('采样到第一个和第二个的概率:%f'%p_12)
print('采样到第一个和第三个的概率:%f'%p_13)
# 采样到第一个和第二个的概率:0.983567
# 采样到第一个和第三个的概率:0.923823
然而,对于一个大小为$n$的集合,一共有$2^{n}$种组合,如何快速地进行 DPP 的计算以及如何最快找到大小为$k$的多样性最大的子集是比较困难的,留给下一篇 post